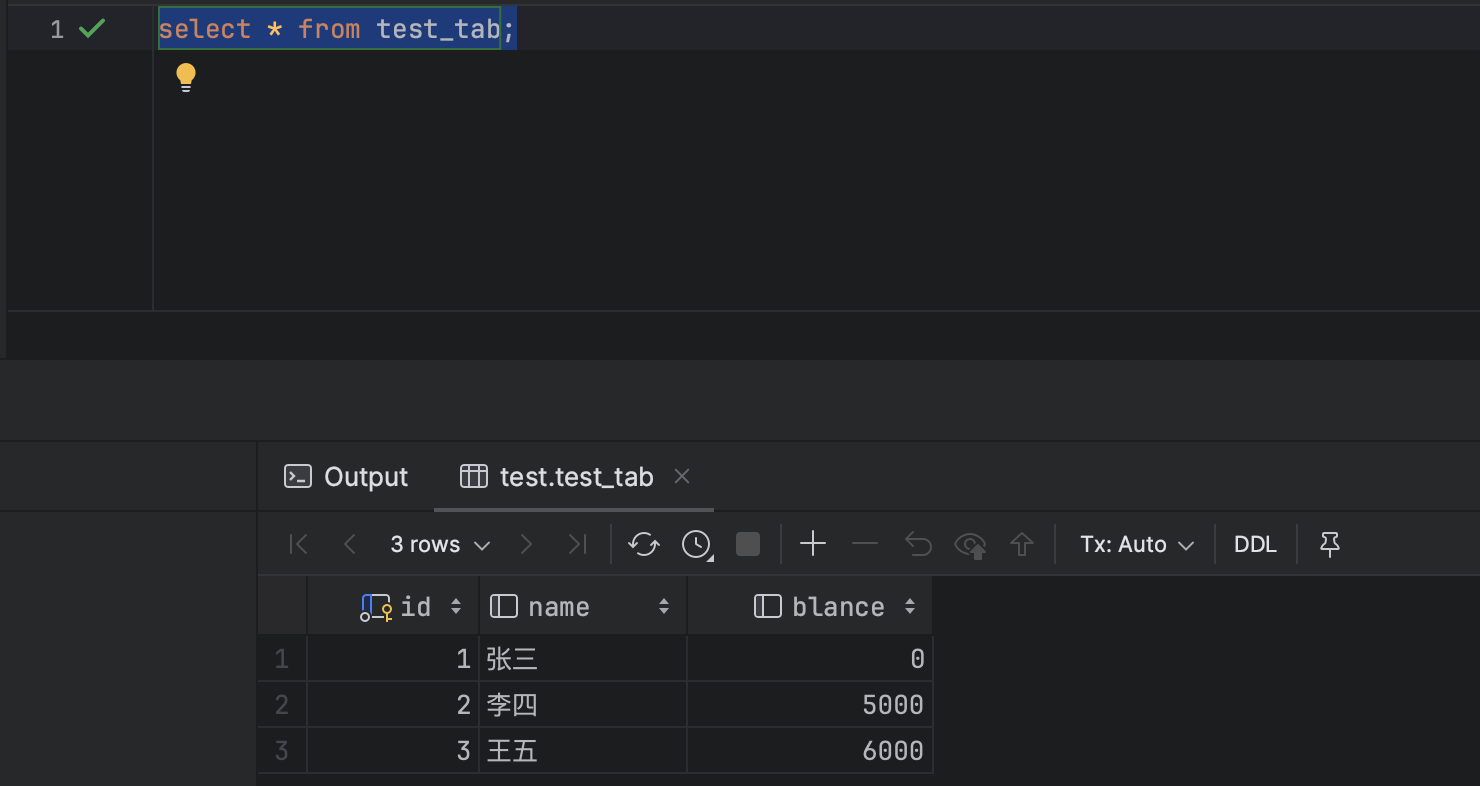
一组数据库操作要么全部成功,要么全部失败,目的是为了保证数据的最终一致性
InnoDB引擎中提供了四种隔离级别,级别越高事务的隔离行越好,但性能就越低,而隔离性是由mysql的各种锁以及MVCC机制来实现
set tx_isolation = 'read-uncommitted';
begin;
update test_tab set blance = blance + 500 where id =1;
commit ;
set tx_isolation = 'read-uncommitted';
begin ;
select * from test_tab where id = 1;
commit ;
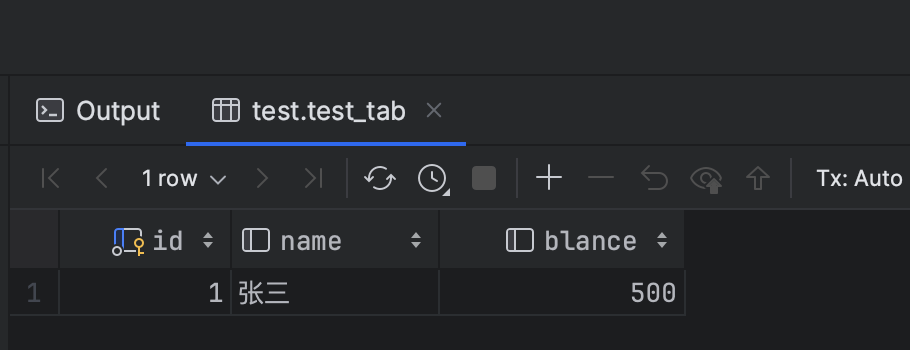
在事务修改sql事务未提交的情况下,查询结果是更新后的数据。在修改未提交事务时,被另一个事务读去到结果,可见是错误。脏读也就是写的事务未提交时,被另一个事务读区到结果。
set tx_isolation = 'read-committed';
begin;
update test_tab set blance = blance + 500 where id =1;
commit ;
set tx_isolation = 'read-committed';
begin ;
select * from test_tab where id = 1;
commit ;
执行步骤:
1、开启一个事务,在事务中更新数据,不提交事务。再开启一个事务,查询正在更新的那条数据,不提交事务。
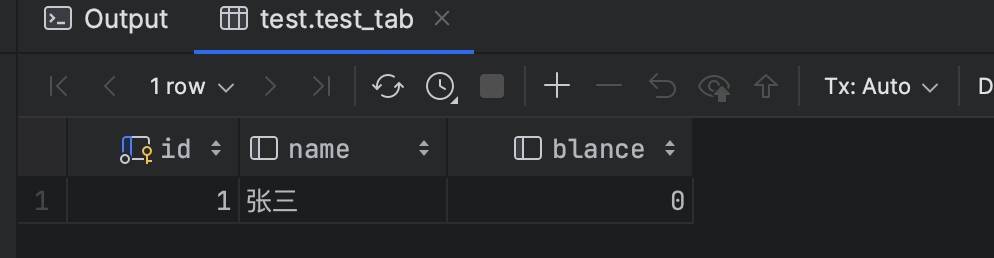
2、步骤1更新数据的事务提交,再次查询那条数据,不提交事务。
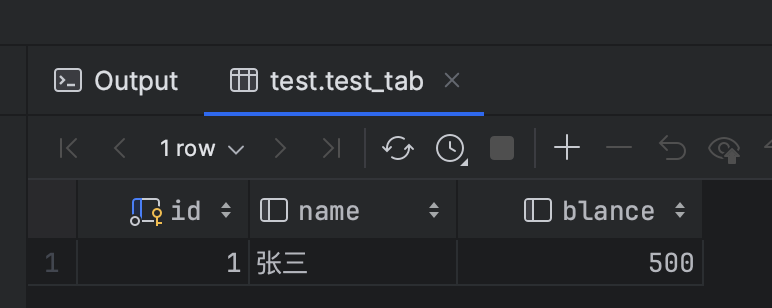
3、步骤1更新语句再次执行,不提交事务。再次查询那条数据,不提交事务。
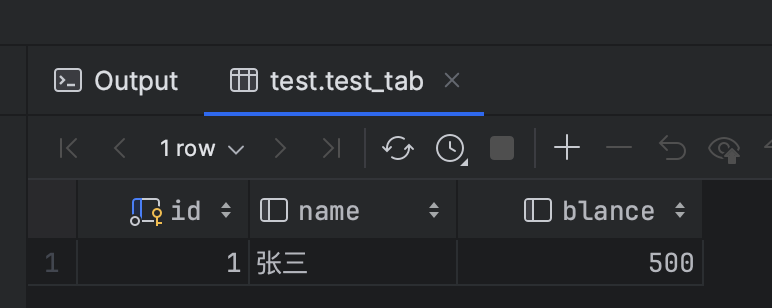
4、步骤3的更新事务提交。再次查询那条数据,不提交事务。
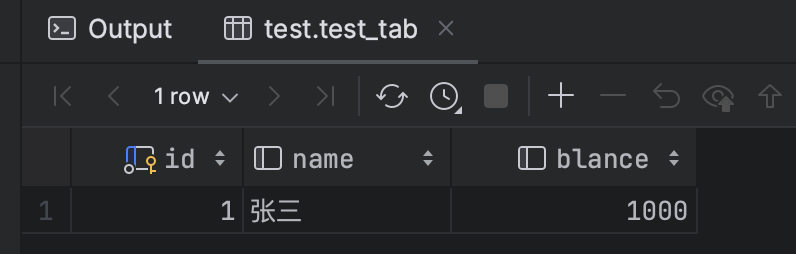
5、查询的事务提交。
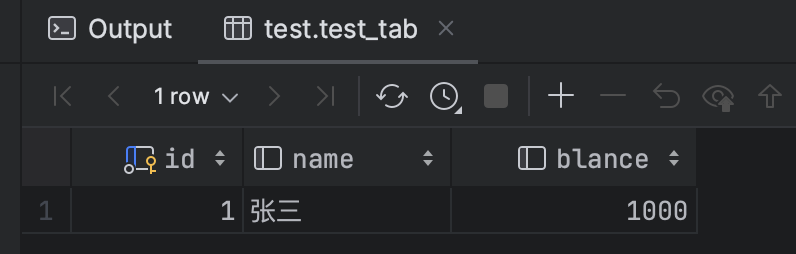
查询的事务无论是否提交,读到的数据都是已经提交事务的数据。
set tx_isolation = 'repeatable-read';
begin;
update test_tab set blance = blance + 500 where id =1;
commit ;
set tx_isolation = 'repeatable-read';
begin ;
select * from test_tab where id = 1;
select * from test_tab where id = 1;
commit ;
select * from test_tab where id = 1;
步骤:
1、1、开启一个事务,在事务中更新数据,不提交事务。再开启一个事务,查询正在更新的那条数据,不提交事务。
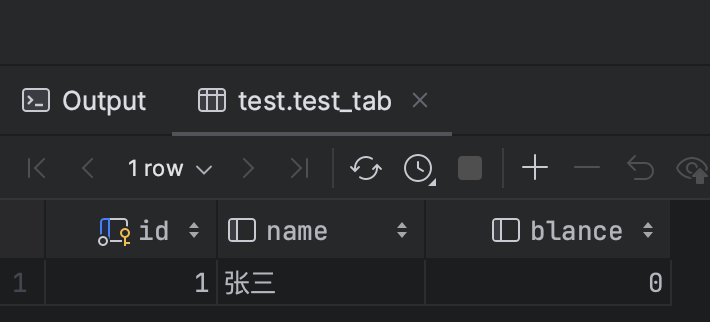
2、2、步骤1更新数据的事务提交,再次查询那条数据,不提交事务。
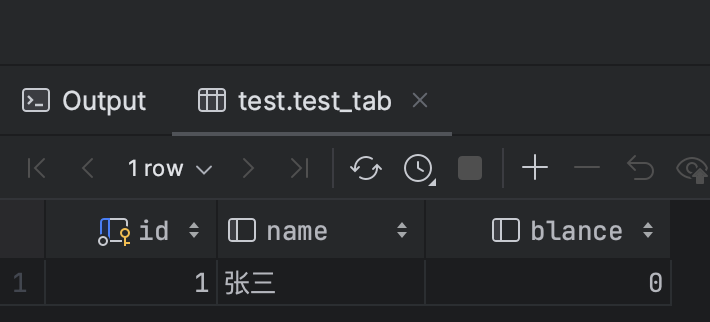
3、步骤1更新语句再次执行,不提交事务。再次查询那条数据,不提交事务。
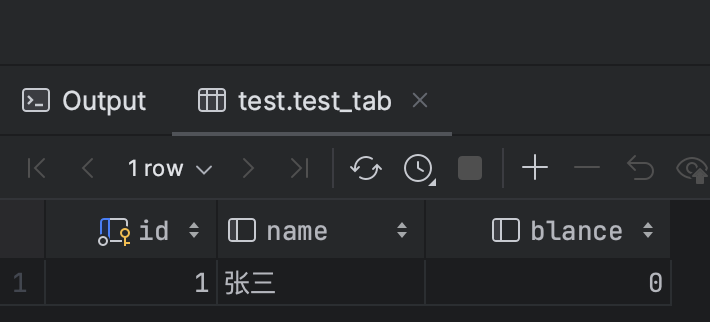
4、步骤3的更新事务提交。再次查询那条数据,不提交事务。
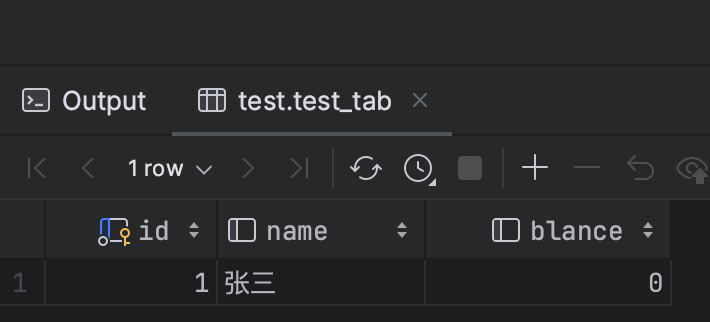
5、查询的事务提交,再次查询。
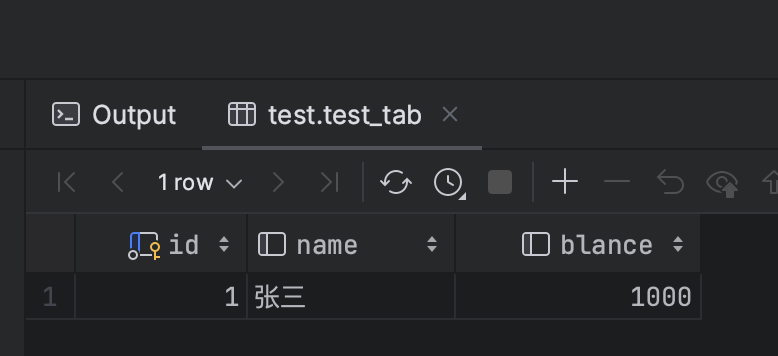
在一个事务里,只要读过了这条数据,后边再读这条数据都以第一次读到的这条数据为主。
那么如何解决这个问题呢?
第一个办法就是用更更高的隔离级别。
第二个办法用乐观锁机制,加上一个version字段,查询的时候将version字段查出来select 业务字段,version from table,更新的时候每次version字段+1 update table set 业务字段, version = version + 1 where version = 前边查出来的version值,知道影响行数大于0。
第三个办法可以使用数据库的悲观锁,如果字段设计到计算的时候,用业务字段 = 业务字段 + 数量,因为mysql的insert、update会有写锁,每次都会用数据库中的最新的数据进行操作
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部