MasaCtrl发布于ICCV2023, 是一个比较老的论文,这里研究这个主要是因为和研究内容相近。我想着是就算方法可能已经没那么新,其中的思想或多或少是可以借鉴的。
MasaCtrl主要致力于解决两个问题:

而MasaCtrl就是致力于同时解决这两个问题,即开发出一种无需微调即能够保持图像一致性的model。
为了实现上述目标,MasCtrl在原有基于LDM的base checkpoint(如sdxl-turbo、 SD1.5等)上做了如下改动:
下面分别对其进行阐述:
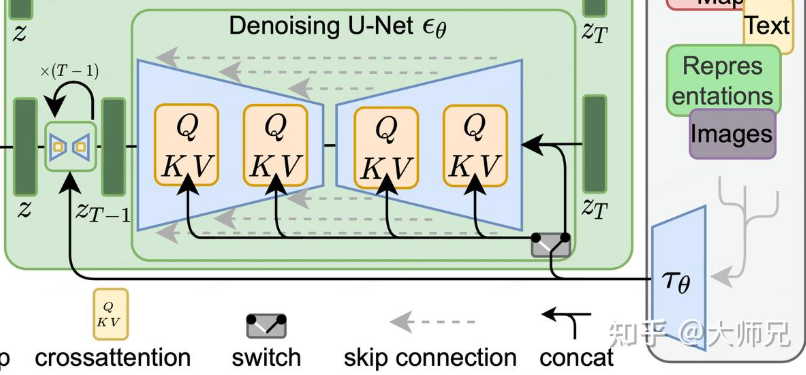
Mutual Self-Attention与Cross-Attention不同,cross-attention是经过embedding后的prompt和(Z_t)的交叉注意力,目的是为了将Prompt融入latent space,以改变扩散方向至prompt要求(如下图)。在扩散过程中,经过Inversion后反向传播 t 时刻的潜在表示(Z_T)可以在训练中得到query矩阵(Q_z),与来自Prompt得到的(presentation-tau_theta)训练得到的矩阵Key, Value(K_tau、Vtau)做公式(1)操作:
(text{CrossAttention}(Q_z, K_tau, V_tau) = text{softmax}left( frac{Q_z K_tau^T}{sqrt{d_z}} right) V_tau tag{1}) (1)
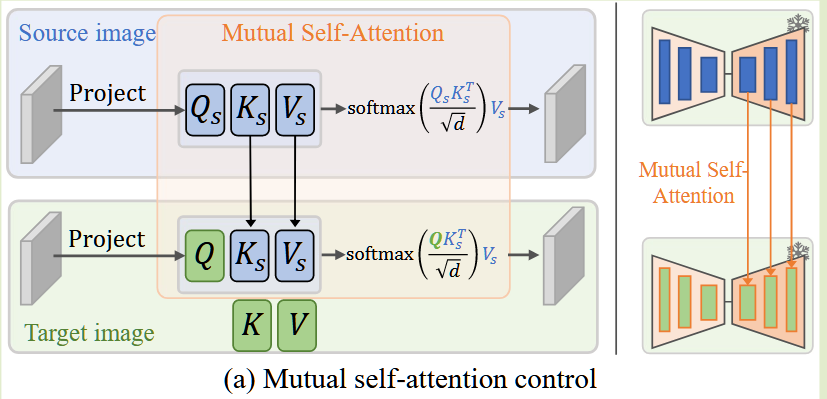
而mutual self-attention则不同,它所做的是两个扩散过程中,同步位点之间的注意力操作。首先生成一幅图像或反转一幅真实图像,形成源图像合成的扩散过程(DP1)和生成新图像或编辑现有图像的新扩散过程(DP2)中,可以使用 DP2 自特征中的查询特征来查询 DP1 自特征中相应的 Key 和 Value 特征。如下图,也就是对Target图像中的(Q,让他与Source图像中的K_S,V_S)进行点积运算(text{CrossAttention}(Q, K_S, V_S)),以在训练后得到保留源图像特征元素的,并带有新提示词生成的semantic layout的新的(Z_0)。
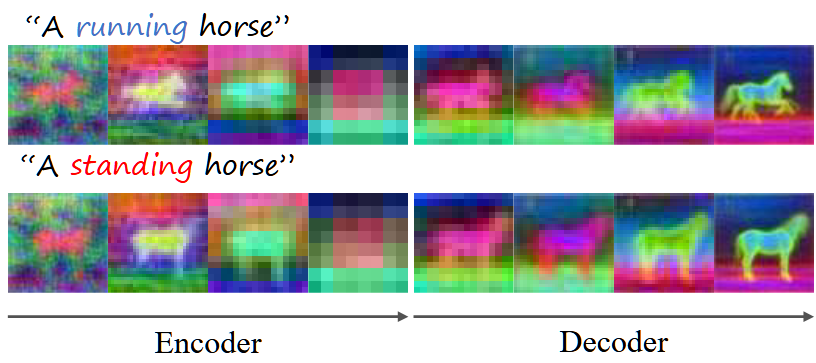
值得注意的是,Mutual Self-Attention之被设计在了Unet的decoder部分,这是因为可以观察到 U-Net 浅层(如编码器部分)的query特征太过于抽象,无法获得与修改后的提示相对应的清晰布局和结构(如下图所示)。因此无法获得所需的layout。因此在decoder阶段才更好。
Key: foreground and the background, segment
为什么在进行复杂的non-rigid操作时新图像不容易保持与原图像的一致性呢?这主要是因为背景和对象的相似程度过高,因此对foreground和background进行segment是一个可行的方法。作者从参考文献([10], [32])中了解到,与提示词相关的cross-attention maps包含了大部分的结构信息, 因此利用语义交叉注意图创建一个掩码,以区分源图像 (I_s) 和目标图像 (I) 中的foreground和background。
这个是我感觉最有用的部分,就算是不适用MasaCtrl的方法,这个思想也感觉会有用的。我们的课题任务其实也是foreground和background的平衡关系。最重要的是小图的内容:在前面的实验中,一直有一个问题,那就是模型生成的图像具有一定的不稳定性。见下图:本来应该是每个小图都是一只完整的猫,然后共同构成一只被隐藏的大猫。但是蓝色框内生成了一只猫的局部,而且红色框内生成的猫几乎是看不到的。虽然这应该是因为总体优化损失函数导致和小图失衡,但是如果借助cross-attention的segment,对找到这个大图小图平衡的位点,说不定有奇效。

接下来是具体操作:
首先还是两个Prompt:生成原图的(P_S和生成目标图的P)分别经过交叉注意力在U-net中前向传播。同时每个token各自得到一张分辨率为16x16的交叉注意力图(如下例),然后对其平均分别得到总的、由(P_S)与生成原图的(U-net)计算交叉注意力得到的(Mask:M_S和P与生成target图像的U-net计算得到的Mask:M),亦如下图:

然后经由下面三个公式得到最终的交叉注意力输出(overline{f^{l}}):
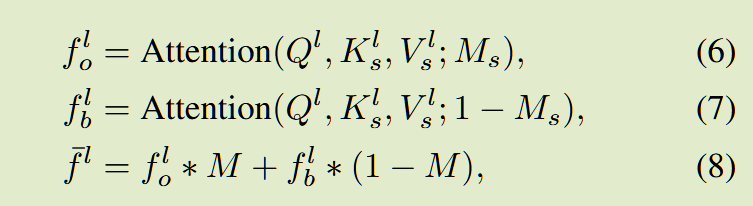
其中(f^{l}_o代表前景部分,f^{l}_b代表背景部分),因此在实际计算时,前景和背景各司其职,对在分割后自己的区域做交叉注意力查询,即公式8。就可以解决对前景和背景的混淆导致的一致生成失败。
然后是Pipeline的陈述: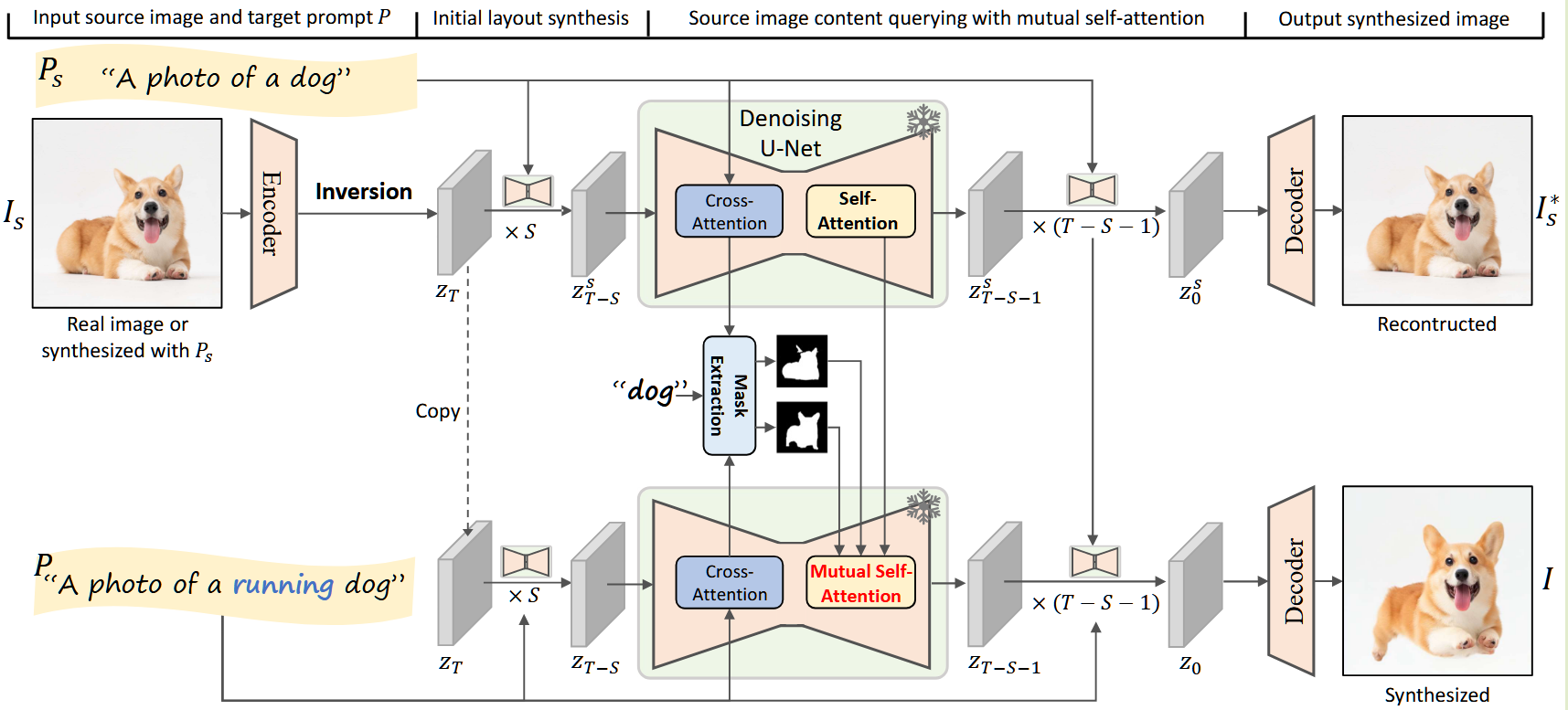
其实已经很清晰了,原图(I_S在经过Encoder,Inversion后得到潜在表示的编码Z_T), 先经过T个(U-net)直接正常去噪,走LDM、(Decoder)得到重建图像(I^*_S)。而对于(edit图像I),为了在能得到合适的Layout后再进行Mutual Self-Attention操作,选取恰当的起点S。即在(t = T - S) 以后,对于每一个(P_S)和(P)提示词下的(U-net,在 encoder 部分)与提示词做交叉注意力查询操作,得到(M和M_S)后通过公式6-8得到最终的(overline{f^{l}}),并在decoder中与前面说的逐层对应的(text{CrossAttention}(Q, K_S, V_S))合流。如此反复经过剩下的(T - S)步后,得到生成的target图像(I).
这里额外说一下对免微调的思考:为什么LoRA需要微调、Imagic需要微调,但是MasaCtrl不需要微调?
微调对模型的再训练会改变原有参数,引入新的参数。因为LoRA引入新的风格,这是原有生成图像中所没有的,因此他需要通过微调。而根据我的理解,保持图像的一致性,起码在理论上是个可以不需要微调的事情,因为在原图上已经给出了足够的关于原图的信息。不得不承认,微调是一个在想不出合适的对图中信息最大化利用的情况下一个解决方案。而为了避免微调这样多此一举的事情。应该在不动原参数的情况下。将需要保持一致的信息提取出来。因此他们设计了Mutual Self-Attention和mask来提取原图、新图,以及前景、背景这些结构信息。感觉这个思考是有推广价值的。
免微调另一个好处是可以更好的跟Controlnet等结合,以控制姿势。
(可不可能完成Controlnet和大模型的交互以生成姿势以更好的卡像素位置即让小图主体自带的颜色与其大图对应位置的颜色更相符?)
原论文没有给出涨点的表格,也没有消融实验。最后放几张实验结果:
多模型对比:

结合Controlnet等的实例:

上面提到的两篇可能作为依据的重要参考文献:
[10] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
[32] Raphael Tang, Akshat Pandey, Zhiying Jiang, Gefei Yang, Karun Kumar, Jimmy Lin, and Ferhan Ture. What the daam: Interpreting stable diffusion using cross attention. arXiv preprint arXiv:2210.04885, 2022.
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部