论文地址 https://arxiv.org/abs/2503.14476
参考实验:DAPO + vLLM v1 + VeRL —— VOC性能比较
没有完整的GRPO训练R1-32B的框架
目标:
整体优化目标如下
其中
[r_{i,t}(theta)=frac{pi_{theta}(o_{i,t}|q,o_{i, 这里DAPO剔除了KL散度惩罚项,它认为 在RLHF场景下,RL的目标是在不偏离原是模型分布下对齐人类偏好(即仅学习人类偏好,而不改变模型原有知识能力),因此需要添加KL惩罚项。 然而在训练long-cot的reasoning模型时,其目标是为了提升模型的能力(math、推理、code等)训练前后的模型分布可以是显著不一样的,KL惩罚项可能会限制模型的探索新知识的能力,因此去除。 分为以下四个方面 考虑到clip的是一个概率的比值(frac{pi_{theta}}{pi_{old}}),在(pi_{old})不同的情况下,会影响clip的范围 例如 (pi_{old}=0.1, pi_{theta}=0.2), 此时比值为(2),此时policy会认为模型前后变化过大,而不训练此数据。但这条数据是值得训练的,只是old的概率比较小。 虽然比值是2倍,但其实数值上只多了0.1,因此还是需要被训练的,并没有影响收敛。 同时,实验也验证了上面发现的问题。实验发现GRPO中 被clip掉的token的平均概率的最大值均小于0.2 ,即 [max_{step}[mathbb{E}_{(q,a)sim mathcal{D}, {o_i}_{i=1}^Gsim pi_{old}(cdot|q),tsim |o_i|}pi_{theta}(o_{i,t}|q,o_{i, 大量小概率的token被clip掉了,这验证了(epsilon_{high})阻碍了低概率token 概率的增长。 因此可以提高上限(epsilon_{high})来提高A>0的低概率token的概率,从而避免entropy变小的过快,输出单一化。 值得注意的现象,提高(epsilon_{higher})之后: 此外,old模型小概率sample并没有影响原有(epsilon_{low}) 考虑到如果一个sample的G个rollout的奖励 ({R_i}_{i=1}^G)都是0或都是1,那么所有的优势A都是0,这并不会更新policy,会导致效率低下 因此使用动态采样的方法,一直采样直到一个sample的G个rollout的R 不全是0 或不全是1. [0 上述公示的含义是,对于QA对((q,a)),(o_i)和答案(a)相同的个数在((0,G))的区间内。 DAPO任务 sample-level的loss(每个rollout的贡献度是一样的),然后不同rollout的长度不一样,过长的样本对模型的影响更大一些: 因此使用token-level的技术,长度越大的rollout,贡献度越大。 通过grpo sample-level loss得知,grpo并不在意response的长短(不同长度的sample的贡献度均为相同),然而长度越长A越大,因此response的长度会快速的增加。 但是DAPO认为长度越长的sample的贡献度越大,因此过长的sample是对的会重点强化(提高概率),但是错了的话,会重点惩罚,从而减小错的长response的概率,即 同时,通过实验发现,DAPO的response的平均长度并没有无脑、快速增长。 考虑到过长的response会被截断无法得到结果,这会导致奖励极低, 实验发现,添加overlong filter之后,训练更加稳定(entropy,acc上),避免了noise。 DAPO进一步提出了soft overlong punishment,其实是基于长度的奖励,就不用进行filter操作了,直接赋予低的R就可以了,有利于降低response的长度。添加了一个cache的缓冲区,从而soft。 [R(y) = begin{cases}
0, &|y|leq L_{max}-L_{cache}\
-frac{|y|-(L_{max}-L_{cache})}{L_{cache}}, &L_{max}-L_{cache} 代码解析待更新(verl实现dapo部分)1. Raise the Ceiling: Clip-Higher
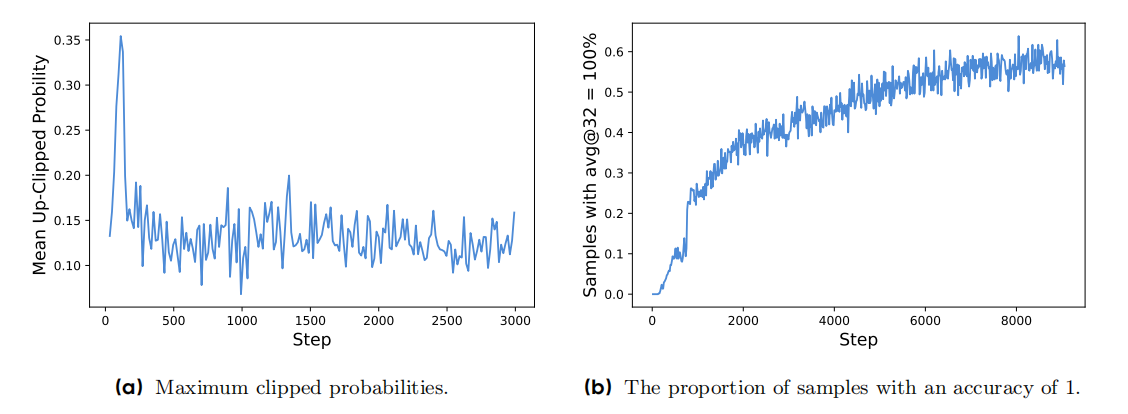
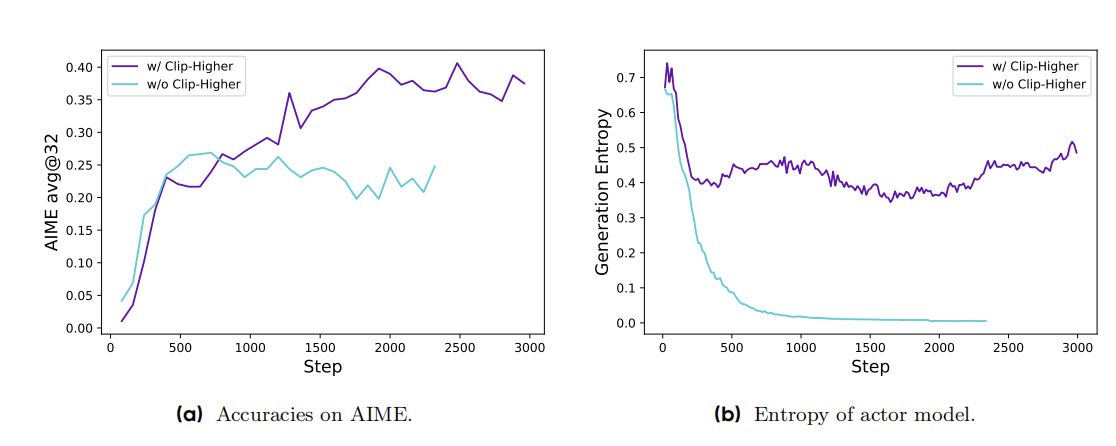
这是因为,(epsilon_{low})是在A若重要性采样的比值很大,并不会对A2. The More the Merrier: Dynamic Sampling
3. Rebalancing Act: Token-Level Policy Gradient Loss
(P(len(o_i)>delta|A下降。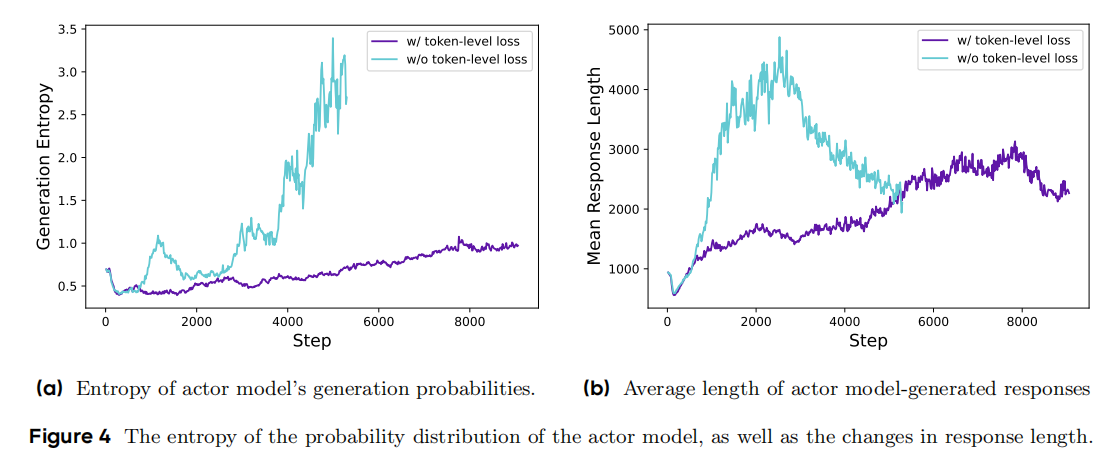
Hide and Seek: Overlong Reward Shaping
因此采用mask的方式,在训练的时候过滤掉过长response的损失。
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部