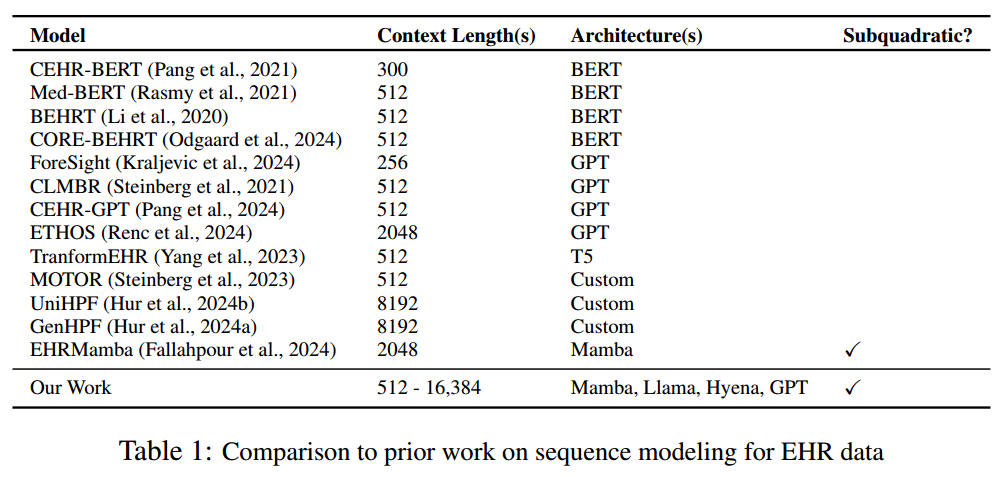
CONTEXT CLUES: EVALUATING LONG CONTEXT MODELS FOR CLINICAL PREDICTION TASKS ON EHRS

该文章于2025年发表在ICLR(CCF A),早在2024年12月发布在arxiv。
文章地址:[Context Clues: Evaluating Long Context Models for Clinical Prediction Tasks on EHR Data](https://proceedings.iclr.cc/paper_files/paper/2025/hash/91a5bb5e5939cb075f5f2464d7b8bbf0-Abstract-Conference.html)
arXiv:[2412.16178] Context Clues: Evaluating Long Context Models for Clinical Prediction Tasks on EHRs
代码仓库:som-shahlab/hf_ehr: Training HuggingFace models on EHR data
openreview打分: 6 10 6 8 5
在医疗领域大模型的评估和尝试。首先,探索了更长的上下文模型可以提高预测性能(基于Mamba模型)。其次,在先前在模型上未充分探索的三个EHR属性进行进一步分析(1.“复制转发”诊断的流行,在EHR序列内有大量重复。2.EHR事件之间的不规则时间间隔,两个事件之间可能相差1天、一年等。3.疾病的复杂性随时间自然增加)。此外,用结构化EHR构建模型的词汇表,训练EHR序列大模型。
研究的核心问题:对医疗领域大模型在三方面的评估和尝试(长上下文、EHR属性的影响、EHR建模)
背景:
1.用于EHR的基础模型
基础模型(FM)是通过无监督学习在大量未标记数据上训练的大规模深度学习模型,在本文中,只考虑结构化EHR数据(忽略笔记、图像等)。现如今的大多数基于EHR数据的序列建模框架使用基于Transformer的架构,如BERT或GPT,在数百万EHR数据上用因果语言建模或掩码语言建模进行预训练。
2.长上下文的基础模型
更长的上下文已经显示出通过使模型能够推理更多的信息来积极影响基础模型的性能,token级别的困惑度随着上下文长度增加而减少,说明更长的序列提高模型的理解能力。从理论上讲,更多了解患者病史也应该有助于更好的临床决策,成本也对应提高。为此,已经有提出针对较长上下文而优化的次二次架构,利用线性或对数线性的方法替换的Transformer中的注意力机制,但这些架构很大程度上仍未在EHR数据上测试。
1.考虑到医院的计算资源有限,现如今基于EHR数据的模型通常上下文长度不高,例如512。但是单个病人的EHR长度可能达到10K的token,极大的限制了这些基础模型。
2.这些基础模型也没考虑最先进的次二次架构,减少成本。
3.与自然语言相比,EHR数据表现出特定类型的标记重复和噪声,使较长上下文的预期好处复杂化。对此没有更深入的分析
1.针对挑战1、2,提出利用次二次架构的Mamba模型,并且进一步将token数扩展到16384,来探索上下文长度对EHR数据建模的影响。
2.针对挑战3,本文探索了三个未充分探索的EHR属性的定量分析,包括①.“复制转发”诊断的流行,在EHR序列内有大量重复。②.EHR事件之间的不规则时间间隔,两个事件之间可能相差1天、一年等。③.疾病的复杂性随时间自然增加

数据集由n个患者的EHR数据构成,每个患者的EHR数据包含一系列的事件三元组(事件,医疗实体,数值/分类值),作者称为patient's timeline。

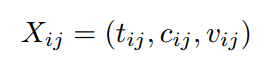
将每一组时间三元组映射到一个token序列上,本文的词汇表用的是先前工作EHRSHOT(一个few-shot基准,用于评测模型在EHR各种任务上的表现,2023)提供的,这样可以和之前SOTA模型公平比较。具体来说,患者每一个临床事件都有一个对应的编码c来表示,在数据集中至少出现一次的所有唯一代码c都被分配了一个唯一的token。与分类值相关的所有代码c都被分配了一个唯一token。与数值相关的代码c,在数据集中获得的值范围内,每十分位数分配一个唯一token。词汇表共记录了39811个token。
本文评估了四种模型,GPT、Llama、Mamba和Hyena。
对于不同模型的上下文长度不同,在预训练时做了截断,预训练使用的是交叉熵损失,以下一个token预测为目标。
使用的是EHRSHOT基准,由15种临床预测任务组成,例如预测ICU转移、30天内再入院,预测实验室检查结果某项指标(血小板减少、贫血)是否异常,预测未来一年内是否会得高血压等新诊断。主要评估指标是AUROC,此外还有Brier(预测与实际结果之间的均方误差)。本文在零样本、少样本和全部 数据设置下评估模型,为了与原始EHRSHOT一致,只是在基础模型之上训练一个逻辑回归头。
对于之前划分的三种EHR特性,首先,应用于EHR-OMOP验证集,衡量真实世界EHR大规模语料在多大程度上表现出这些特性。其次,将其中两种属性重复性和不规则形应用于EHRSHOT数据集,以根据每个病人表现出这些特征的程度进行分层,这种分层能够使我们评估模型性能如何随着这些特征水平的不同而变化。
数据集:EHR-OMOP,从一个学术医疗中心按照OMOP格式化后的数据集。
EHRSHOT,一个few-shot学习基准数据集

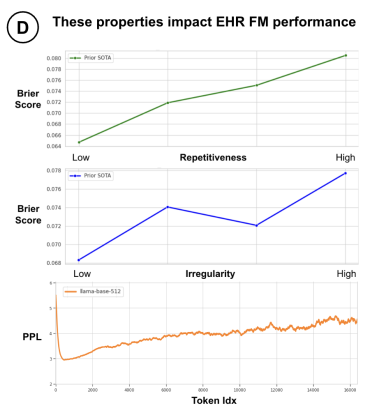
EHR数据表现出比自然语言更高的重复程度

将患者EHR重复率由低到高分为四个阶段

EHR-OMOP数据集中的关于不规则性的时间数据统计
三种方法;每个患者的事件间隔时间的平均值,标准差和四分位数范围

表2将这一分析扩展到在这项工作中训练的EHR FM。虽然模型性能仍然随着不规则性的增加而下降,但在所有四分位数中,Mamba和Llama的较长上下文版本始终优于其较短的对应版本。
患者时间轴中较晚的token更难预测(更高的困惑度)
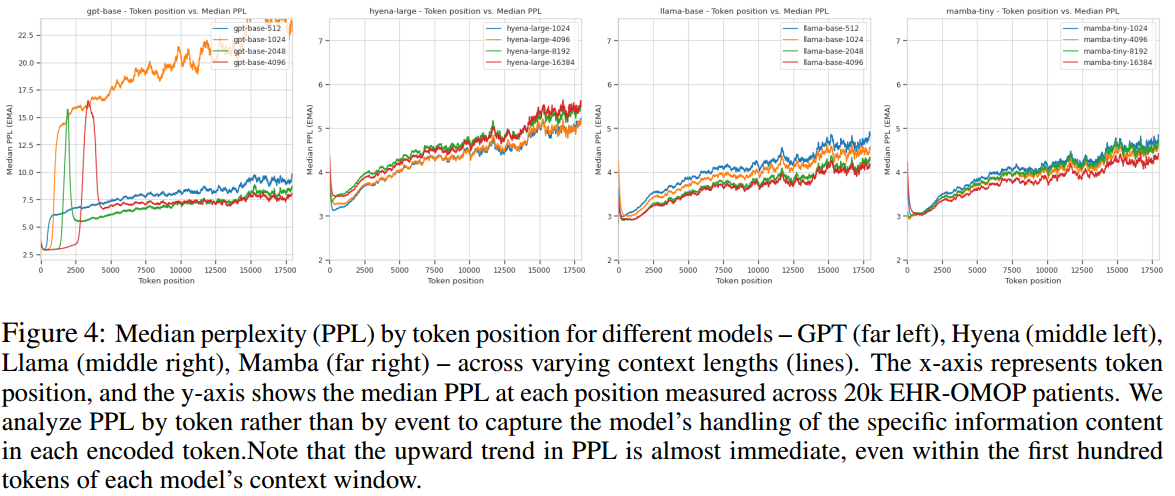
与较短的上下文相比,较长的上下文版本的Mamba和Llama在所有标记位置上始终实现较低的困惑度,并且在较晚的标记处差距扩大。这表明更完整的患者时间轴视图有助于处理由于老化而增加的标记复杂度。相比之下,Hyena的较长上下文模型表现较差,复制了我们最初的EHRSHOT结果。对于GPT,结果好坏参半:较长上下文(2k和4k)在后面的token上实现了较低的困惑,但表现出显著的尖峰。这似乎是由GPT使用绝对位置嵌入引起的-用旋转位置嵌入(ROPE)取代它们。
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部