近期关于智能体设计有诸多观点,一个关键点让我豁然开朗——无论智能体是1个还是多个,是编排驱动还是自主决策,是静态预定义还是动态生成,Context上下文的管理机制始终是设计的核心命脉。它决定了:每个节点使用哪些信息?分别更新或修改哪些信息?多步骤间如何传递?智能体间是否共享、如何共享?后续篇章我们将剖析多个热门开源项目,一探它们如何驾驭Context。本章聚焦单智能体设计,选取两个代表性框架:模仿OpenAI深度研究范式的Gemini-fullstack(编排式)与模仿Manus的OpenManus(自主式)。
先来整体对比下两个框架,这样懒得看细节的盆友们就可以只看下表了~
| 特性 | Gemini Deep Search (编排式) | OpenManus Flow Mode (规划式自主) | OpenManus Manus Mode (纯自主) |
|---|---|---|---|
| 智能体类型 | 单智能体,编排驱动 | 单智能体,全局规划 + 分步ReAct循环 | 单智能体,ReAct循环 |
| 任务分解 | 固定流程节点 | 全局Plan | 动态思考下一步(Think) |
| Context 范围 | 节点级隔离 (每节点用特定输入) | Step级隔离 (每Step用Plan状态+当前任务) | 线性增长+窗口截断 (全历史) |
| Context 传递 | 传递任务结果 (Query列表, 摘要文本) | 外层:传递Plan状态 + Step结果字符串;内层全部历史 | 传递完整ReAct历史 (截断后) |
| 状态管理 | 无显式状态,依赖数据流 | 显式Plan & Step状态管理 | 隐含在消息历史中 |
| 优势 | 流程清晰可控,模块化,引用处理优雅 | 步骤Context轻量,潜在减少迭代次数 | 灵活性高 |
| 挑战 | 灵活性较低,节点间“思考”不共享 | Plan质量依赖(或需要动态调整),Step间Context隔离可能导致信息断层/冲突 | Context膨胀,长程依赖易丢失,多轮消息会引入噪音 |
Gemini Deep Search 是一个典型的编排式智能体。其执行流程预先定义,核心在于引入了反思节点,用于动态判断信息收集是否充分。流程清晰简洁:
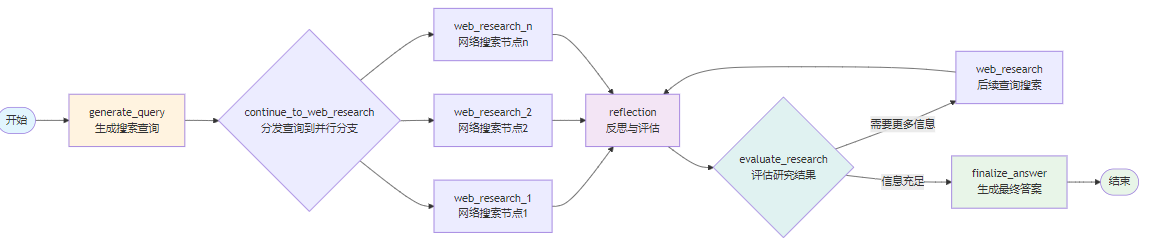
图释:Gemini Deep Search的核心编排流程,包含查询生成、并行搜索、反思评估、路由决策和最终答案生成五个关键节点,通过反思节点实现循环控制。

class SearchQueryList(BaseModel):
query: List[str] = Field(
description="A list of search queries to be used for web research."
)
rationale: str = Field(
description="A brief explanation of why these queries are relevant to the research topic."
)
实际应用中会发现把 思考工具化(结构化) 有很多优点:

然后就是基于多个query的并行搜索模块这里直接使用了Langgraph自带的Send多线程并发模式,然后直接让大模型基于检索上文进行总结。这里可参考不多,因为引用生成等逻辑在Gemini的API中,用开源模型的盆友需要重新适配。
不过有意思的是现在如何给模型推理插入引用,原来多数都是在指令中加入要求,让模型一边推理一边生成引用序号[i]([citation:i]),不过在新的模型能力下有了很多天马星空的方案。像Claude给出过先直接进行无引用推理,然后再让模型重新基于推理结果,在不修改原文的基础上,插入引用的markdown链接。
这里Google是直接推理API中集成了类似能力,哈哈我也没用过Gemini的API,不过看代码,应该是类似以下的结构, 会通过结构化推理(哈哈Google很爱用结构化推理,其实个人也觉得不论是工具还是Function Calling或者是Thinking,最底层的对接方案还是结构化推理),返回引用序号列表对应的文字段落的起止位置。
# Gemini API响应结构
response.candidates[0].grounding_metadata = {
"grounding_supports": [
{
"segment": {"start_index": 0, "end_index": 50},
"grounding_chunk_indices": [0, 1, 2]
}
],
"grounding_chunks": [
{
"web": {
"uri": "https://example.com/page1",
"title": "Example Page 1"
}
}
]
}
考虑到这里涉及两次模型推理,第一次就是每个query的搜索总结,第二次是最终基于所有总结段落的二次汇总推理。因此这里项目在本次推理(第一次)中把citation以markdown超链接的格式插回到了原文中,这样二次推理可以直接生成引用链接。(URL进行了缩写,降低推理token和copy出错的可能性)

class Reflection(BaseModel):
is_sufficient: bool = Field(
description="Whether the provided summaries are sufficient to answer the user's question."
)
knowledge_gap: str = Field(
description="A description of what information is missing or needs clarification."
)
follow_up_queries: List[str] = Field(
description="A list of follow-up queries to address the knowledge gap."
)
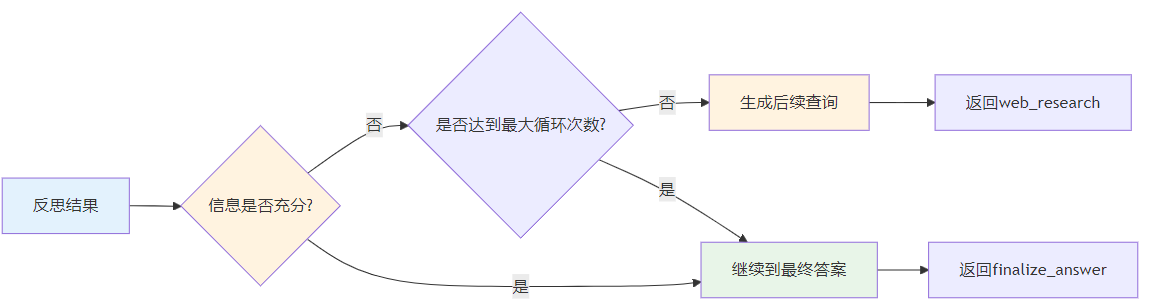

Gemini的Context管理
OpenManus 提供了两种模式:Manus Mode(基础ReAct)和Flow Mode(规划驱动)。虽然项目将Flow称为“多智能体”,但从Context管理角度看,更像是单智能体的两种任务分解策略:Manus是局部规划+即时执行,Flow是全局规划(Plan)+分步执行(Manus)。
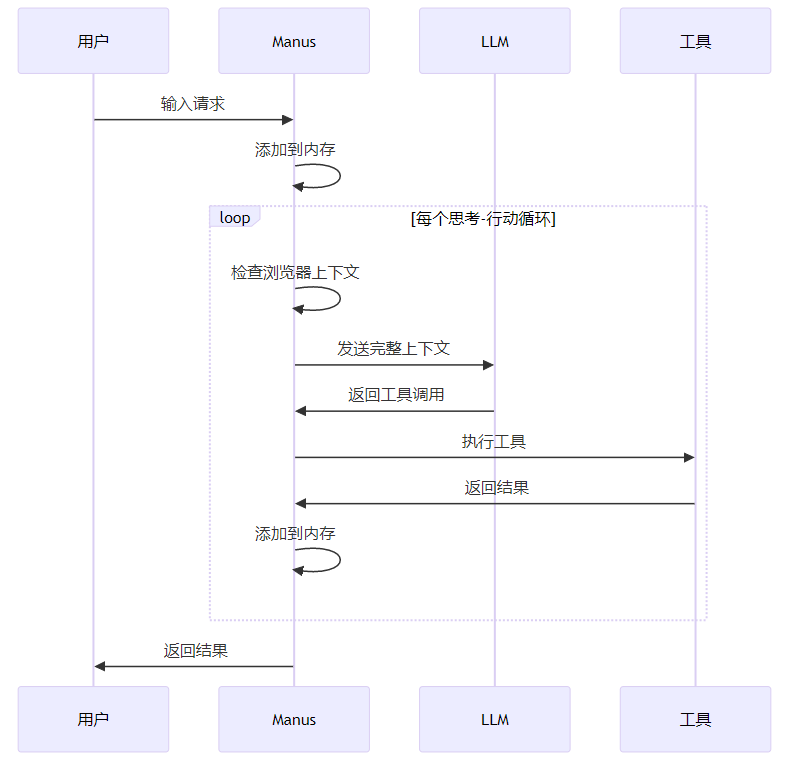
Manus模式本质是ReAct循环:思考(Think)->行动(Act)->观察(Observe),循环执行直至任务完成。核心流程:
Manus的Context管理
线性增长: 整个任务由一个智能体完成,Context随执行步骤线性增长,每一步都使用前置的所有message信息。

Flow的核心思想是引入全局Plan规划器。在当前模型能力下,先规划再执行有助于:
Plan工具设计 (核心): Plan本身通过结构化工具实现管理:
class PlanningTool(BaseTool):
"""
A planning tool that allows the agent to create and manage plans for solving complex tasks.
The tool provides functionality for creating plans, updating plan steps, and tracking progress.
"""
name: str = "planning"
description: str = _PLANNING_TOOL_DESCRIPTION
parameters: dict = {
"type": "object",
"properties": {
"command": {
"description": "The command to execute. Available commands: create, update, list, get, set_active, mark_step, delete.",
"enum": [
"create",
"update",
"list",
"get",
"set_active",
"mark_step",
"delete",
],
"type": "string",
},
"plan_id": {
"description": "Unique identifier for the plan. Required for create, update, set_active, and delete commands. Optional for get and mark_step (uses active plan if not specified).",
"type": "string",
},
"title": {
"description": "Title for the plan. Required for create command, optional for update command.",
"type": "string",
},
"steps": {
"description": "List of plan steps. Required for create command, optional for update command.",
"type": "array",
"items": {"type": "string"},
},
"step_index": {
"description": "Index of the step to update (0-based). Required for mark_step command.",
"type": "integer",
},
"step_status": {
"description": "Status to set for a step. Used with mark_step command.",
"enum": ["not_started", "in_progress", "completed", "blocked"],
"type": "string",
},
"step_notes": {
"description": "Additional notes for a step. Optional for mark_step command.",
"type": "string",
},
},
"required": ["command"],
"additionalProperties": False,
}
下面我们来看下Plan创建、遍历、更新的整个流程
system_message = Message.system_message(
"You are a planning assistant. Create a concise, actionable plan with clear steps. "
"Focus on key milestones rather than detailed sub-steps. "
"Optimize for clarity and efficiency."
)
# Create a user message with the request
user_message = Message.user_message(
f"Create a reasonable plan with clear steps to accomplish the task: {request}"
)
step_prompt = f"""
CURRENT PLAN STATUS:
{plan_status}
YOUR CURRENT TASK:
You are now working on step {self.current_step_index}: "{step_text}"
Please execute this step using the appropriate tools. When you're done, provide a summary of what you accomplished.
"""
Flow的Context管理
Reference
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部