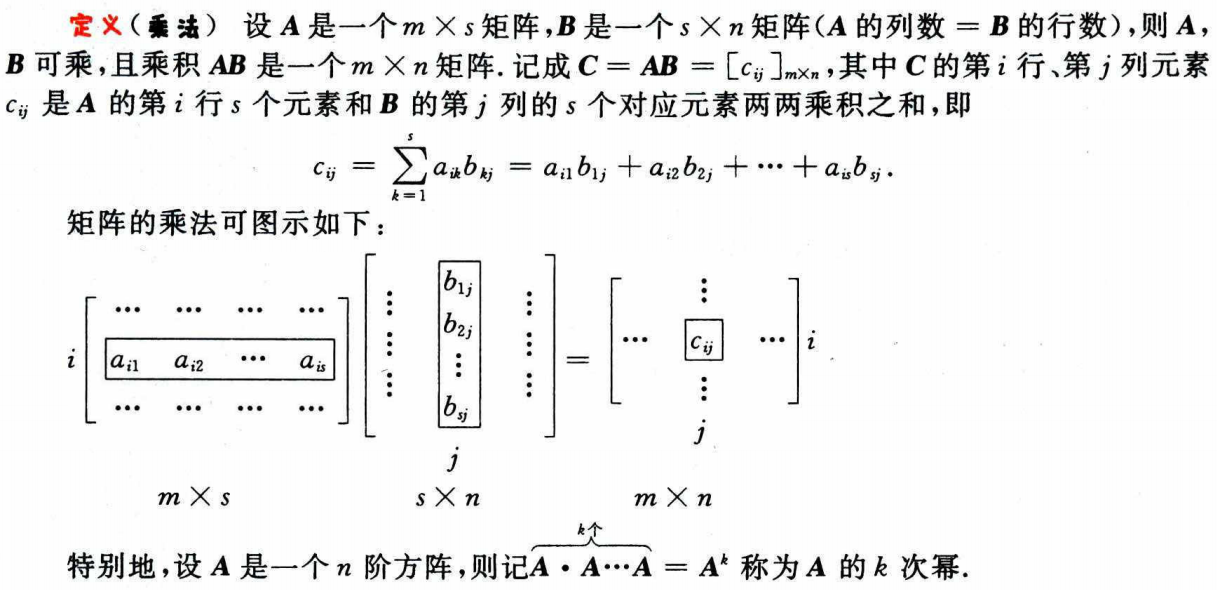
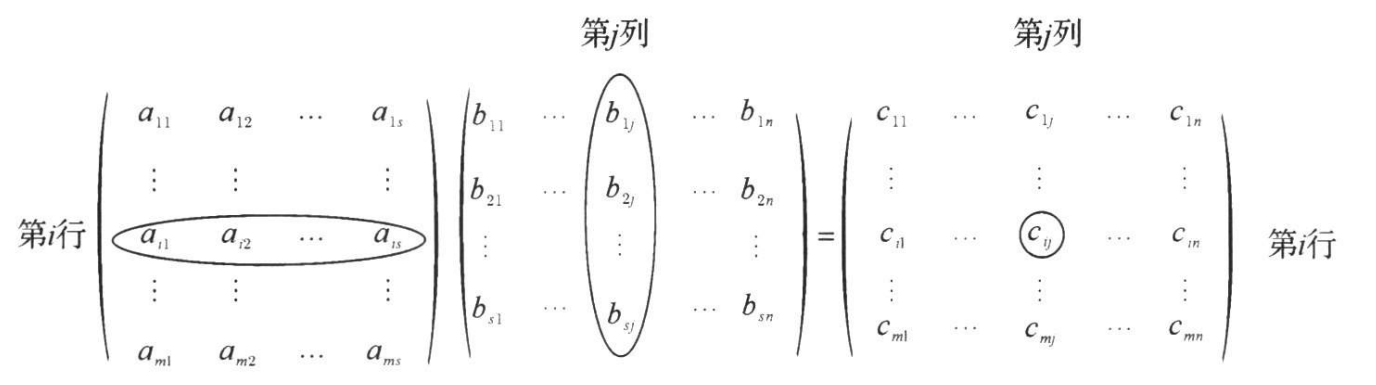
(这系列文章所有的内容是深度学习用的数学知识,都在实数域上讨论问题,且从数学专业的人的角度来看)
这是我听课的笔记,也有一些自己补充的内容(课程地址:https://www.bilibili.com/cheese/play/ss32496)
由(mtimes n)个数(a_{i j(i=1,2, cdots, m ; j=1,2, cdots, n)})排成(m)行、(n)列的数表称为(m)行(n)列的矩阵,简称(mtimes n)型矩阵。一维数表一般称为向量,但是也可以称为行矩阵(行向量)或列矩阵(列向量),三维及以上数表则称为张量(tensor)。(特指深度学习中的定义,不是物理中的张量),为了区别矩阵、向量和数的区别,矩阵一般用大写粗体字母表示,比如矩阵(boldsymbol{A}),而向量一般用粗体小写字母表示,比如(boldsymbol{a}),数用小写非粗体字母表示,比如(a).(当然向量也可以用粗体大写字母表示,而(1times 1)矩阵,既是一个数,又是一个矩阵,所以它既可以用粗体大写字母表示,又可以用非粗体小写字母表示,比较灵活),矩阵既可以用方括号括起来,也可以用圆括号括起来,比较灵活,向量也是同理,比如:(begin{array}{l}
left[begin{array}{lll}
a_{11} & a_{12} & a_{13} \
a_{21} & a_{22} & a_{23} \
a_{31} & a_{32} & a_{33}
end{array}right]\
end{array})和(begin{array}{l}
left(begin{array}{lll}
a_{11} & a_{12} & a_{13} \
a_{21} & a_{22} & a_{23} \
a_{31} & a_{32} & a_{33}
end{array}right)\
end{array})是同一个矩阵,写作的方法不一样罢了。

其中,我们可以发现,一个矩阵是由若干个行向量或者列向量构成的,比如:(begin{array}{l}
left[begin{array}{lll}
a_{11} & a_{12} & a_{13} \
a_{21} & a_{22} & a_{23} \
a_{31} & a_{32} & a_{33}
end{array}right]\
end{array}=begin{array}{l}
left[begin{array}{l}
boldsymbol{a_1} \
boldsymbol{a_2} \
boldsymbol{a_3}
end{array}right]\
end{array},boldsymbol{a_1}=[a_{11} , a_{12} , a_{13}],boldsymbol{a_2}=[a_{21} , a_{22} , a_{23}],boldsymbol{a_3}=[a_{31} , a_{32} , a_{33}])(行向量的向量的各分量(元素)可以用空格隔开,也可以用逗号隔开,比较随意,我这里用了逗号写法,没有统一的写法,当年我学线代,最烦没有统一的写法,如今也被迫适应了,而且当时线代老师也不讲这些写法啊或者是和后面章节联动的细节,线代学的云里雾里)或
(begin{array}{l}
left[begin{array}{lll}
a_{11} & a_{12} & a_{13} \
a_{21} & a_{22} & a_{23} \
a_{31} & a_{32} & a_{33}
end{array}right]\
end{array}=begin{array}{l}
left[begin{array}{l}
boldsymbol{a_1} & boldsymbol{a_2} & boldsymbol{a_3}
end{array}right]\
end{array},boldsymbol{a_1}=left[begin{array}{l}
a_{11}\
a_{21}\
a_{31}
end{array}right],boldsymbol{a_2}=left[begin{array}{l}
a_{12} \
a_{22} \
a_{32}
end{array}right],boldsymbol{a_3}=left[begin{array}{lll}
a_{13} \
a_{23} \
a_{33}
end{array}right]).
把一组行(列)向量放在一起称为向量组,比如({boldsymbol{a}_1,boldsymbol{a}_2,boldsymbol{a}_3})就是一个向量组,把一组行向量放在一起称为行向量组,把一组列向量放在一起称为列向量组,我们可以看出,刚才的矩阵和行列向量的关系就已经说明了向量组实际上可以用矩阵来表示,也就是(begin{array}{l}
left[begin{array}{lll}
a_{11} & a_{12} & a_{13} \
a_{21} & a_{22} & a_{23} \
a_{31} & a_{32} & a_{33}
end{array}right]\
end{array}=begin{array}{l}
left[begin{array}{l}
boldsymbol{a}_1 \
boldsymbol{a}_2 \
boldsymbol{a}_3
end{array}right]\
end{array},boldsymbol{a_1}=[a_{11} , a_{12} , a_{13}],boldsymbol{a_2}=[a_{21} , a_{22} , a_{23}],boldsymbol{a_3}=[a_{31} , a_{32} , a_{33}])这种形式,相当于是将行向量组({boldsymbol{a}_1,boldsymbol{a}_2,boldsymbol{a}_3})。用矩阵(begin{array}{l}
left[begin{array}{lll}
a_{11} & a_{12} & a_{13} \
a_{21} & a_{22} & a_{23} \
a_{31} & a_{32} & a_{33}
end{array}right]\
end{array}=begin{array}{l}
left[begin{array}{l}
boldsymbol{a}_1 \
boldsymbol{a}_2 \
boldsymbol{a}_3
end{array}right]\
end{array})来表示,同理也有把列向量组用矩阵表示的方法。
下面介绍一些深度学习中常见的矩阵。
【注】矩阵从左上角开始到右下角的对角线称为矩阵的主对角线,如果是从右上角开始到左下角的对角线称为矩阵的副对角线
[left[begin{array}{lll} 1 & 0 & 0 \ 0 & 1 & 0 \ 0 & 0 & 1 end{array}right] ]
[left[begin{array}{ccc} a_{11} & Delta & bigcirc \ Delta & a_{22} & square \ bigcirc & square & a_{33} end{array}right] ]
[left[begin{array}{ccc} a_{11} & 0 & 0 \ 0 & a_{22} & 0 \ 0 & 0 & a_{33} end{array}right] ]
[left[begin{array}{cccc} a_{11} & a_{12} & cdots & a_{1 n} \ 0 & a_{22} & cdots & a_{2 n} \ vdots & vdots & vdots & vdots \ 0 & 0 & cdots & a_{m n} end{array}right] ]
[left[begin{array}{cccc} a_{11} & 0 & cdots & 0 \ a_{21} & a_{22} & cdots & 0 \ vdots & vdots & vdots & vdots \ a_{m 1} & a_{m 2} & cdots & a_{m n} end{array}right] ]
单位阵、对称阵一定是方阵,三角阵、对角阵通常是方阵。有些特殊形式的矩阵也称为标准型,如对角阵、(若尔当)Jordan块(会在后面矩阵分解模块介绍)等。后面说把矩阵化为标准型,实际上就是把矩阵化成对角阵等等。
[boldsymbol{A}pm boldsymbol{B}=left[a_{i j}right]_{m times n}pm left[b_{i j}right]_{m times n}=left[a_{i j}pm b_{i j}right]_{m times n} ]
【注】在PyTorch框架中(boldsymbol{A}_{mtimes n}+boldsymbol{C}_{1times 1})是可以求出来的,因为PyTorch框架中,将(boldsymbol{C}_{1times 1})广播为(boldsymbol{C}_{mtimes n}),其中(boldsymbol{C})中的元素均相等(因为(boldsymbol{C}_{1times 1})是(1times 1)矩阵,它就是一个数),这是PyTorch框架的特性而不是本身矩阵运算所定义的。[begin{aligned} lambda A & =A lambda=lambdaleft[begin{array}{cccc} a_{11} & a_{12} & cdots & a_{1 n} \ a_{21} & a_{22} & cdots & a_{2 n} \ vdots & vdots & & vdots \ a_{m 1} & a_{m 2} & cdots & a_{m n} end{array}right]=left[begin{array}{cccc} lambda a_{11} & lambda a_{12} & cdots & lambda a_{1 n} \ lambda a_{21} & lambda a_{22} & cdots & lambda a_{2 n} \ vdots & vdots & & vdots \ lambda a_{m 1} & lambda a_{m 2} & cdots & lambda a_{m n} end{array}right] \ & =left(lambda a_{i j}right)_{m times n}, end{aligned} ]
[left[begin{array}{lll} 1 & 2 & 3 \ 2 & 5 & 8 end{array}right]left[begin{array}{cc} 1 & 2 \ -1 & 3 \ 2 & 7 end{array}right]=left[begin{array}{ll} 1 times 1+2 times(-1)+3 times 2 & 1 times 2+2 times 3+3 times 7 \ 2 times 1+5 times(-1)+8 times 2 & 2 times 2+5 times 3+8 times 7 end{array}right]=left[begin{array}{cc} 5 & 29 \ 13 & 75 end{array}right] ]
但当(boldsymbol{A}boldsymbol{B}=boldsymbol{0})((boldsymbol{0})这种粗体的数字0表示元素均为0的向量、矩阵或者张量)时,不一定有(boldsymbol{A}=boldsymbol{0})或(boldsymbol{B}=boldsymbol{0}),换句话说,当(boldsymbol{A}ne boldsymbol{0})且(boldsymbol{B}ne boldsymbol{0})时仍有可能(boldsymbol{A}boldsymbol{B}=boldsymbol{0}),这和数乘不一样;若(r=m),也就是(boldsymbol{A}_{mtimes n},boldsymbol{B}_{ntimes m}),通常(boldsymbol{A}boldsymbol{B}ne boldsymbol{B}boldsymbol{A}),即矩阵乘法没有交换律。矩阵乘法虽然十分特殊,但它仍具有以下性质:[(boldsymbol{A} boldsymbol{B}) boldsymbol{C}=boldsymbol{A}(boldsymbol{B} boldsymbol{C}) ]
[ lambda(boldsymbol{A} boldsymbol{B})=(lambda boldsymbol{A}) boldsymbol{B}=boldsymbol{A}(lambda boldsymbol{B}) ]
[ boldsymbol{A}(boldsymbol{B}pm boldsymbol{C})=boldsymbol{A} boldsymbol{B}pm boldsymbol{A} boldsymbol{C}, quad(boldsymbol{B}pm boldsymbol{C}) boldsymbol{A}=boldsymbol{B} boldsymbol{A}pm boldsymbol{C} boldsymbol{A} ]
[left[begin{array}{cccc} a_{11} & a_{12} & cdots & a_{1 n} \ a_{21} & a_{22} & cdots & a_{2 n} \ vdots & vdots & vdots & vdots \ a_{m 1} & a_{m 2} & cdots & a_{m n} end{array}right] xrightarrow{boldsymbol{A}^{T}}left[begin{array}{cccc} a_{11} & a_{21} & cdots & a_{m 1} \ a_{12} & a_{22} & cdots & a_{m 2} \ vdots & vdots & vdots & vdots \ a_{1 n} & a_{2 n} & cdots & a_{m n} end{array}right] ]
[begin{array}{l} left(boldsymbol{A}^{T}right)^{T}=boldsymbol{A} \ (boldsymbol{A}+boldsymbol{B})^{T}=boldsymbol{A}^{T}+boldsymbol{B}^{T} \ (lambda boldsymbol{A})^{T}=lambda boldsymbol{A}^{T} \ (boldsymbol{A} boldsymbol{B})^{T}=boldsymbol{B}^{T} boldsymbol{A}^{T} end{array} ]
【注】((boldsymbol{A} boldsymbol{B})^{T}=boldsymbol{B}^{T} boldsymbol{A}^{T}ne boldsymbol{A}^{T} boldsymbol{B}^{T}),这是因为矩阵乘法中没有交换律。
对于方阵(boldsymbol{A}),若存在一个(n)阶方阵(boldsymbol{B})使得(boldsymbol{A}boldsymbol{B}=boldsymbol{B}boldsymbol{A}=boldsymbol{I}),则说明矩阵(boldsymbol{A})是可逆的,把(boldsymbol{B})称为(boldsymbol{A})的逆矩阵,记作(boldsymbol{A}^{-1}).
[boldsymbol{B}=boldsymbol{B}boldsymbol{I}=boldsymbol{B}(boldsymbol{A}boldsymbol{C})=(boldsymbol{B}boldsymbol{A})boldsymbol{C}=boldsymbol{I}boldsymbol{C}=boldsymbol{C} ]
[left[begin{array}{cc:ccc:c} 1 & 2 & 0 & 0 & 0 & 0 \ 2 & 5 & 0 & 0 & 0 & 0 \ hdashline 0 & 0 & 2 & 0 & 1 & 0 \ 0 & 0 & 3 & -2 & 1 & 0 \ 0 & 0 & 0 & 1 & 2 & 0 \ hdashline 0 & 0 & 0 & 0 & 0 & 2 end{array}right]=left[begin{array}{ccc} boldsymbol{A}_{11} & boldsymbol{A}_{12} & boldsymbol{A}_{13}\ boldsymbol{A}_{21} & boldsymbol{A}_{22} & boldsymbol{A}_{23}\ boldsymbol{A}_{31} & boldsymbol{A}_{32} & boldsymbol{A}_{33} end{array}right] ]
其中(boldsymbol{A}_{11}=left[begin{array}{cc} 1 & 2\ 2 & 5 end{array}right]),(boldsymbol{A}_{12}=left[begin{array}{ccc} 0 & 0 & 0\ 0 & 0 & 0 end{array}right]),(boldsymbol{A}_{13}=left[begin{array}{c} 0\ 0 end{array}right]),(boldsymbol{A}_{21}=left[begin{array}{cc} 0 & 0 \ 0 & 0 \ 0 & 0 end{array}right]),(boldsymbol{A}_{22}=left[begin{array}{cc} 2 & 0 & 1\ 3 & -2 & 1 \ 0 & 1 & 2 end{array}right]),(boldsymbol{A}_{23}=left[begin{array}{cc} 0\ 0\ 0 end{array}right]),(boldsymbol{A}_{31}=left[begin{array}{cc} 0 & 0 end{array}right]),(boldsymbol{A}_{32}=left[begin{array}{ccc} 0 & 0 & 0 end{array}right]),(boldsymbol{A}_{33}=left[begin{array}{c} 2 end{array}right])
[left(begin{array}{ll} boldsymbol{A}_{11} & boldsymbol{A}_{12} \ boldsymbol{A}_{21} & boldsymbol{A}_{22} end{array}right)^{-1} neqleft(begin{array}{ll} boldsymbol{A}_{11}^{-1} & boldsymbol{A}_{12}^{-1} \ boldsymbol{A}_{21}^{-1} & boldsymbol{A}_{22}^{-1} end{array}right), quadleft(begin{array}{cc} boldsymbol{A}_{11} & boldsymbol{A}_{12} \ 0 & boldsymbol{A}_{22} end{array}right)^{-1}=left(begin{array}{cc} boldsymbol{A}_{11}^{-1} & -boldsymbol{A}_{11}^{-1} boldsymbol{A}_{12} boldsymbol{A}_{22}^{-1} \ 0 & boldsymbol{A}_{22}^{-1} end{array}right) ]
[left(boldsymbol{A}^{-1}right)^{-1}=boldsymbol{A}, quad(lambda boldsymbol{A})^{-1}=frac{1}{lambda} boldsymbol{A}^{-1}, quad(boldsymbol{A} boldsymbol{B})^{-1}=boldsymbol{B}^{-1} boldsymbol{A}^{-1} ]
非方阵可以定义左逆、右逆、伪逆,这些概念统称为矩阵的广义逆。
[boldsymbol{A}_{L}^{-1}=boldsymbol{X}boldsymbol{A}=boldsymbol{I} ]
[boldsymbol{A}_{R}^{-1}=boldsymbol{A}boldsymbol{X}=boldsymbol{I} ]
【补】线性相关与线性无关:设有一组向量(boldsymbol{alpha}_1,boldsymbol{alpha}_2,cdots,boldsymbol{alpha}_n),如果存在不全为(0)的数(k_1,k_2,cdots,k_n),使得(k_1boldsymbol{alpha}_1+K_2boldsymbol{alpha}_2+cdots+k_nboldsymbol{alpha}_n=boldsymbol{0}),则称这一组向量(boldsymbol{alpha}_1,boldsymbol{alpha}_2,cdots,boldsymbol{alpha}_n)是线性相关的,否则,当(k_1=k_2=cdots=k_n=0)(全为0)时,(boldsymbol{alpha}_1,boldsymbol{alpha}_2,cdots,boldsymbol{alpha}_n)线性无关。结合一些例子更好理解,比如在2/3维空间中,线性相关时向量共线/共面;线性无关时向量不共线/不共面。性质:一组向量如果包括含零向量则该组向量相关、向量数量超过空间维数必相关等。
线性无关的直观理解:一组向量“线性无关”,意味着它们无法通过相互“缩放”和“相加”得到零向量,除非每个向量的系数都是0。 比如二维向量(boldsymbol{a}=(1,0))和(boldsymbol{b}=(0,1))线性无关(无法用(kboldsymbol{a} + lboldsymbol{b} = mathbf{0})除非(k=l=0)),而(boldsymbol{c}=(1,2))和(boldsymbol{d}=(2,4))线性相关(因为(boldsymbol{d}=2boldsymbol{c}))。
【补】向量的极大线性无关组(又简称为极大无关组):极大线性无关组是在线性空间中拥有向量个数最多的线性无关向量组。(就是一个向量组中拿出去一些向量拼成若干个线性无关的向量的组合,这些组合都是线性无关的,这些组合中向量个数最多的组合是向量的极大线性无关组,向量的极大线性无关组是不唯一的)
【补】矩阵的秩(Rank):在线性代数中,一个矩阵(boldsymbol{A})的列秩是(boldsymbol{A})对应的列向量组的极大无关组的向量个数,通常表示为(r(boldsymbol{A}))或(text{rank} boldsymbol{A}).
【补】矩阵的行向量的极大无关组的向量个数是矩阵的行秩,矩阵列向量的极大无关组的向量个数是列秩,列秩等于行秩;矩阵的秩有如下公式:(r(boldsymbol{A}^{T}boldsymbol{A})=r(boldsymbol{A}boldsymbol{A}^{T})=r(boldsymbol{A}))
【补】矩阵满秩、行满秩与列满秩:设(boldsymbol{A})是n阶矩阵, 若(r(boldsymbol{A})) = n, 则称(boldsymbol{A})为满秩矩阵。但满秩不局限于(n)阶矩阵。若矩阵秩等于行数,称为行满秩;若矩阵秩等于列数,称为列满秩。既是行满秩又是列满秩则为(n)阶矩阵即(n)阶方阵。行满秩矩阵就是行向量线性无关,列满秩矩阵就是列向量线性无关;所以如果是方阵,行满秩矩阵与列满秩矩阵是等价的。
关于左右可逆有如下重要性质:
关于左右逆阵不唯一,举例说明:设有矩阵(boldsymbol{A}=left(begin{array}{lll} 4 & 0 & 0 \ 0 & 5 & 0 end{array}right)),它是右可逆(其行向量线性无关,所以它是右可逆的)但不是左可逆的,并且右可逆矩阵是不唯一的,通常,一个矩阵左可逆不代表右可逆,或者右可逆也不代表左可逆,并且左右逆矩阵不一定唯一,比如(left(begin{array}{lll} 4 & 0 & 0 \ 0 & 5 & 0 end{array}right)left(begin{array}{cc} frac{1}{4} & 0 \ 0 & frac{1}{5} \ c_{31} & c_{32} end{array}right)=left(begin{array}{ll} 1 & 0 \ 0 & 1 end{array}right)),其中(c_{31})与(c_{32})是任意常数。
证明“若(boldsymbol{A})左(右)可逆,则(boldsymbol{A}^{T}boldsymbol{A})((boldsymbol{A}boldsymbol{A}^{T}))是可逆的”:
若(boldsymbol{A}_{m times n})左可逆,则(A)一定列满秩,又因为
(rleft(boldsymbol{A}^{T} boldsymbol{A}right)=r(boldsymbol{A})),
所以(boldsymbol{A}^{T} boldsymbol{A})的秩为(n),故(boldsymbol{A}^{T} boldsymbol{A})是满秩方阵(因为(boldsymbol{A})是(mtimes n)型矩阵,(boldsymbol{A}^{T})是(ntimes m)型矩阵,所以(boldsymbol{A}^{T}boldsymbol{A})是(ntimes n)型的方阵),因此它一定可逆。实际上有
[boldsymbol{A}_{L}^{-1}=left(boldsymbol{A}^{T} boldsymbol{A}right)^{-1} boldsymbol{A}^{T} longrightarrow boldsymbol{A}_{L}^{-1} boldsymbol{A}=left(boldsymbol{A}^{T} boldsymbol{A}right)^{-1} boldsymbol{A}^{T} boldsymbol{A}=left(boldsymbol{A}^{T} boldsymbol{A}right)^{-1}left(boldsymbol{A}^{T} boldsymbol{A}right)=I ]
类似地,对于右可逆的情况,有
[boldsymbol{A}_{R}^{-1}=boldsymbol{A}^{T}left(boldsymbol{A} boldsymbol{A}^{T}right)^{-1} longrightarrow boldsymbol{A} boldsymbol{A}_{R}^{-1}=boldsymbol{A} boldsymbol{A}^{T}left(boldsymbol{A} boldsymbol{A}^{T}right)^{-1}=left(boldsymbol{A} boldsymbol{A}^{T}right)left(boldsymbol{A} boldsymbol{A}^{T}right)^{-1}=I ]
证明“若(boldsymbol{A})同时左右可逆,则它一定是可逆方阵,左右逆就是其逆”:若(boldsymbol{A})同时左右可逆,则说明(boldsymbol{A})既列满秩且行满秩,因此(boldsymbol{A})一定是方阵且满秩,故它可逆。
【补】向量的内积:设两个n维向量:
(boldsymbol{a} = (a_1, a_2, dots, a_n))
(boldsymbol{b} = (b_1, b_2, dots, b_n))
则(boldsymbol{a})与(boldsymbol{b})的内积记作 (boldsymbol{a} cdot boldsymbol{b}),定义为:
[boldsymbol{a} cdot boldsymbol{b} = a_1b_1 + a_2b_2 + dots + a_nb_n = sum_{i=1}^{n} a_ib_i ]
同样地,对于两个(n)维列向量:
(boldsymbol{a} = begin{pmatrix}a_1 \ a_2 \ vdots \ a_nend{pmatrix})
(boldsymbol{b} = begin{pmatrix}b_1 \ b_2 \ vdots \ b_nend{pmatrix})
它们的内积可以表示为向量(boldsymbol{a})的转置与向量(boldsymbol{b})的矩阵乘法:
[boldsymbol{a} cdot boldsymbol{b} = boldsymbol{a}^T boldsymbol{b} = begin{pmatrix}a_1 & a_2 & cdots & a_nend{pmatrix} begin{pmatrix}b_1 \ b_2 \ vdots \ b_nend{pmatrix} = sum_{i=1}^{n} a_i b_i ]
【补】向量的模:对于n维向量(boldsymbol{x}=(x_1, x_2, dots, x_n)),其模长记作(|boldsymbol{x}|),定义为:
[|boldsymbol{x}| = sqrt{x_1^2 + x_2^2 + dots + x_n^2} ]
本质:向量各分量平方和的算术平方根,保证结果非负。 向量的模写成(|boldsymbol{x}|)也是可以的,比较灵活。
【补】向量的模长和内积的关系:向量的模长可以通过内积表示:
[|boldsymbol{x}|^2 = boldsymbol{x} cdot boldsymbol{x} = boldsymbol{x}^T boldsymbol{x} ]
解释:向量与自身的内积等于模长的平方。例如,二维向量(boldsymbol{a}=(3,4)):
[boldsymbol{a}^T boldsymbol{a} = begin{pmatrix}3 & 4end{pmatrix}begin{pmatrix}3 \ 4end{pmatrix} = 3^2 + 4^2 = 25 = |boldsymbol{a}|^2 ]
【补】线性方程组:线性方程组就是由多个“一次方程”组成的方程组。比如:
(2x + 3y = 5)
(4x - y = 1)
这是一个包含2个未知数((x, y))的线性方程组,解这类方程的核心是找到满足所有等式的未知数取值。 当然也可以推广到(n)个未知数,我们用2个未知数的线性方程组来简单地说明问题。
【补】用矩阵表示方程组:上面的方程组可以写成矩阵形式:
[underbrace{begin{pmatrix}2 & 3 \ 4 & -1end{pmatrix}}_{text{矩阵 }boldsymbol{A}} underbrace{begin{pmatrix}x \ yend{pmatrix}}_{text{向量 }boldsymbol{x}} = underbrace{begin{pmatrix}5 \ 1end{pmatrix}}_{text{向量 }boldsymbol{b}} quad text{简记为 } boldsymbol{A}boldsymbol{x} = boldsymbol{b} ]
【补】齐次线性方程组:当等式右边的向量(boldsymbol{b})为零向量(mathbf{0})时,称为齐次线性方程组,例如:
[begin{pmatrix}2 & 3 \ 4 & 6end{pmatrix} begin{pmatrix}x \ yend{pmatrix} = begin{pmatrix}0 \ 0end{pmatrix} ]
这类方程至少有一个解:(boldsymbol{x} = mathbf{0})(称为“零解”),但可能还有其他非零解(如上面的例子中,(x=3, y=-2)也是解)。归结为:齐次线性方程组要么只有零解,要么有无穷多个解。
【补】有关齐次线性方程组(boldsymbol{A}boldsymbol{x}=boldsymbol{0})的只有零解的等价条件(还有别的条件后面用到再补充):
一、从矩阵角度
二、从向量组角度
总结为(以下4个命题互为充要条件):
Gram矩阵: 若(boldsymbol{A})为(m times n)型矩阵,其各列线性无关的充要条件是:(boldsymbol{A})的Gram矩阵((boldsymbol{A}^{T} boldsymbol{A}),为(n times n)型)(注意是(boldsymbol{A}^{T}boldsymbol{A})而不是(boldsymbol{A}boldsymbol{A}^{T})是(boldsymbol{A})的Gram矩阵)是可逆的。Gram矩阵是机器学习中非常常见、非常重要的一个矩阵,它由(n)个列向量的内积构成。设(boldsymbol{A}=(boldsymbol{a}_{1}, boldsymbol{a}_{2}, boldsymbol{a}_{3}, boldsymbol{a}_{4})),则
[boldsymbol{A}^{T} boldsymbol{A} = begin{pmatrix} boldsymbol{a}_{1}^{T} \ boldsymbol{a}_{2}^{T} \ boldsymbol{a}_{3}^{T} \ boldsymbol{a}_{4}^{T} end{pmatrix} (boldsymbol{a}_{1}, boldsymbol{a}_{2}, boldsymbol{a}_{3}, boldsymbol{a}_{4}) = begin{pmatrix} boldsymbol{a}_{1}^{T}boldsymbol{a}_{1} & boldsymbol{a}_{1}^{T}boldsymbol{a}_{2} & boldsymbol{a}_{1}^{T}boldsymbol{a}_{3} & boldsymbol{a}_{1}^{T}boldsymbol{a}_{4} \ boldsymbol{a}_{2}^{T}boldsymbol{a}_{1} & boldsymbol{a}_{2}^{T}boldsymbol{a}_{2} & boldsymbol{a}_{2}^{T}boldsymbol{a}_{3} & boldsymbol{a}_{2}^{T}boldsymbol{a}_{4} \ boldsymbol{a}_{3}^{T}boldsymbol{a}_{1} & boldsymbol{a}_{3}^{T}boldsymbol{a}_{2} & boldsymbol{a}_{3}^{T}boldsymbol{a}_{3} & boldsymbol{a}_{3}^{T}boldsymbol{a}_{4} \ boldsymbol{a}_{4}^{T}boldsymbol{a}_{1} & boldsymbol{a}_{4}^{T}boldsymbol{a}_{2} & boldsymbol{a}_{4}^{T}boldsymbol{a}_{3} & boldsymbol{a}_{4}^{T}boldsymbol{a}_{4} end{pmatrix} ]
Gram矩阵中每一个元素都是由一个行向量和一个列向量做矩阵乘法(其实就是内积)得到的。
即矩阵(boldsymbol{A})有Gram矩阵(Leftrightarrowboldsymbol{A})的各列(各个列向量)线性无关,接下来证明此点:
充分性证明:若 (boldsymbol{A}^{T} boldsymbol{A}) 可逆,则 (boldsymbol{A}) 的各列线性关。等同于证明若 (left(boldsymbol{A}^{T} boldsymbol{A}right)boldsymbol{x} = mathbf{0}) 时一定有 (boldsymbol{x} = mathbf{0}),则 (boldsymbol{A} boldsymbol{x} = mathbf{0}) 时一定有 (boldsymbol{x} = mathbf{0})。假设 (boldsymbol{x}) 使得 (boldsymbol{A} boldsymbol{x} = mathbf{0}),因为
[boldsymbol{A} boldsymbol{x} = mathbf{0} rightarrow boldsymbol{A}^{top} boldsymbol{A} boldsymbol{x} = mathbf{0} ]
(即在等式两侧同时左乘(boldsymbol{A}^{T}))
因为此时一定有 (boldsymbol{x} = mathbf{0}),所以 (boldsymbol{A}) 是列不相关的。
必要性证明:若 (boldsymbol{A}) 的列向量线性无关,则(boldsymbol{A}^{T} boldsymbol{A})是可逆的。等同于证明若 (boldsymbol{A} boldsymbol{x} = mathbf{0}) 时一定有 (boldsymbol{x} = mathbf{0})(齐次线性方程组要么只有零解,要么无穷多解,此处是只有零解的情况),则 (boldsymbol{A}^{T} boldsymbol{A} boldsymbol{x} = mathbf{0}) 时也一定有 (boldsymbol{x} = mathbf{0})。假设 (boldsymbol{x}) 使得 (boldsymbol{A}^{T} boldsymbol{A} boldsymbol{x} = mathbf{0}),因为
[mathbf{0} = boldsymbol{x}^{T} mathbf{0} = boldsymbol{x}^{T} left( boldsymbol{A}^{T} boldsymbol{A} right) boldsymbol{x} = | boldsymbol{A} boldsymbol{x} |^{2} rightarrow boldsymbol{A} boldsymbol{x} = mathbf{0} ]
因为此时 (boldsymbol{A}) 是列不相关的,所以一定有 (boldsymbol{x} = mathbf{0}),所以 (boldsymbol{A}^{T} boldsymbol{A}) 是可逆的。
伪逆:若 $ boldsymbol{A} $ 不为方阵但 $ boldsymbol{A}^{T} boldsymbol{A} $ 可逆,则 $ left(boldsymbol{A}^{T} boldsymbol{A}right)^{-1} boldsymbol{A}^{T} $ 是 $ boldsymbol{A} $ 的一个左逆。令 $ boldsymbol{A}^{dagger} = left(boldsymbol{A}^{T} boldsymbol{A}right)^{-1} boldsymbol{A}^{T} $(像小匕首的符号叫作dagger),它也被称为 $ boldsymbol{A} $ 的伪逆或摩尔-彭尔斯逆(Moore-Penrose):
[left( left( boldsymbol{A}^{top} boldsymbol{A} right)^{-1} boldsymbol{A}^{top} right) boldsymbol{A} = left( boldsymbol{A}^{top} boldsymbol{A} right)^{-1} left( boldsymbol{A}^{top} boldsymbol{A} right) = boldsymbol{I} ]
【补】行列式:行列式是一个与方阵相关的标量值,它描述了矩阵所代表的线性变换对空间的拉伸或压缩程度。只有方阵(行数等于列数)才有行列式。对于方阵(boldsymbol{A}),其行列式可以写成(det{boldsymbol{A}}),也可以写成(|boldsymbol{A}|).
二阶行列式
对于 (2 times 2) 矩阵 $ boldsymbol{A} = begin{pmatrix} a & b c & d end{pmatrix} $,其行列式定义为:
[det(boldsymbol{A}) = begin{vmatrix} a & b \ c & d end{vmatrix} = ad - bc ]
三阶行列式
对于 (3 times 3) 矩阵 $ boldsymbol{A} = begin{pmatrix} a_{11} & a_{12} & a_{13} a_{21} & a_{22} & a_{23} a_{31} & a_{32} & a_{33} end{pmatrix} $,其行列式可按第一行展开:[det(boldsymbol{A}) = begin{vmatrix} a_{11} & a_{12} & a_{13} \ a_{21} & a_{22} & a_{23} \ a_{31} & a_{32} & a_{33} end{vmatrix} = a_{11} begin{vmatrix} a_{22} & a_{23} \ a_{32} & a_{33} end{vmatrix} - a_{12} begin{vmatrix} a_{21} & a_{23} \ a_{31} & a_{33} end{vmatrix} + a_{13} begin{vmatrix} a_{21} & a_{22} \ a_{31} & a_{32} end{vmatrix} ]
二阶行列式和三阶行列式的几何意义
- 二阶行列式:$ begin{vmatrix} a & b c & d end{vmatrix} $ 表示由向量 $ begin{pmatrix} a c end{pmatrix} $ 和 $ begin{pmatrix} b d end{pmatrix} $ 张成的平行四边形的面积。
- 三阶行列式:表示由三个三维向量张成的平行六面体的体积。
(n)阶行列式
对于 $ n times n $ 方阵 $ boldsymbol{A} $,其行列式 $ det(boldsymbol{A}) $ 或记作 $ |boldsymbol{A}| $,是一个描述矩阵性质的重要标量。行列式可以通过递归方式定义:对于 $ n times n $ 矩阵 $ boldsymbol{A} = (a_{ij}) $,其行列式可按第 $ i $ 行展开:
[det(boldsymbol{A}) = sum_{j=1}^{n} a_{ij} cdot C_{ij} quad (i = 1, 2, dots, n) ]
其中 $ C_{ij} = (-1)^{i+j} cdot M_{ij} $ 称为代数余子式,$ M_{ij} $ 是 $ boldsymbol{A} $ 中去掉第 $ i $ 行和第 $ j $ 列后剩余的 $ (n-1) times (n-1) $ 子矩阵的行列式,称为余子式。
行列式的性质
- 行列式为零的充要条件:矩阵的行(或列)向量线性相关
- 行列式的几何意义:$ n $ 阶行列式表示 $ n $ 维空间中由行(或列)向量张成的平行多面体的有向体积
- 行列式与可逆性:方阵 $ boldsymbol{A} $ 可逆当且仅当 $ det(boldsymbol{A}) neq 0 $
计算方法
- 对角线法则(仅适用于2×2和3×3矩阵)
- 余子式展开法(适用于低阶矩阵)
- 高斯消元法(将矩阵转化为上三角形式,行列式等于主对角线元素乘积,后面会提到)
设有向量 $ boldsymbol{a} = left( a_{1}, cdots, a_{n} right)^{T}, boldsymbol{b} = left( b_{1}, cdots, b_{n} right)^{T} $
内积(inner product):
[boldsymbol{a} cdot boldsymbol{b} = sum_{j=1}^{n} a_{j} b_{j} = |boldsymbol{a}| |boldsymbol{b}| cos theta quad text{(结果为标量)} ]
外积(outer product):
[boldsymbol{a} otimes boldsymbol{b} = boldsymbol{a} boldsymbol{b}^{T} quad text{(结果为矩阵)} ]
叉乘积(cross product):
[boldsymbol{a} times boldsymbol{b} = |boldsymbol{a}| |boldsymbol{b}| sin theta cdot boldsymbol{n} quad (boldsymbol{n} text{ 是垂直于 } boldsymbol{a}, boldsymbol{b} text{ 所在平面的单位向量,即法向量}) ]
外积运算示例(以三维向量为例):
[boldsymbol{a} = begin{pmatrix} a_{1} \ a_{2} \ a_{3} end{pmatrix}, quad boldsymbol{b} = begin{pmatrix} b_{1} \ b_{2} \ b_{3} end{pmatrix} quad rightarrow quad boldsymbol{a} otimes boldsymbol{b} = begin{pmatrix} a_{1} \ a_{2} \ a_{3} end{pmatrix} begin{pmatrix} b_{1} & b_{2} & b_{3} end{pmatrix} = begin{pmatrix} a_{1}b_{1} & a_{1}b_{2} & a_{1}b_{3} \ a_{2}b_{1} & a_{2}b_{2} & a_{2}b_{3} \ a_{3}b_{1} & a_{3}b_{2} & a_{3}b_{3} end{pmatrix} ]
叉乘得到垂直于 $ boldsymbol{a}, boldsymbol{b} $ 所在平面的法向量,其模长为 $ |boldsymbol{a} times boldsymbol{b}| = |boldsymbol{a}| |boldsymbol{b}| sin theta $:
[begin{aligned} boldsymbol{a} times boldsymbol{b} & = begin{vmatrix} boldsymbol{i} & boldsymbol{j} & boldsymbol{k} \ a_{1} & a_{2} & a_{3} \ b_{1} & b_{2} & b_{3} end{vmatrix} \ & = begin{vmatrix} a_{2} & a_{3} \ b_{2} & b_{3} end{vmatrix} boldsymbol{i} - begin{vmatrix} a_{1} & a_{3} \ b_{1} & b_{3} end{vmatrix} boldsymbol{j} + begin{vmatrix} a_{1} & a_{2} \ b_{1} & b_{2} end{vmatrix} boldsymbol{k} \ & = (a_{2}b_{3} - a_{3}b_{2}) boldsymbol{i} - (a_{1}b_{3} - a_{3}b_{1}) boldsymbol{j} + (a_{1}b_{2} - a_{2}b_{1}) boldsymbol{k} end{aligned} ]
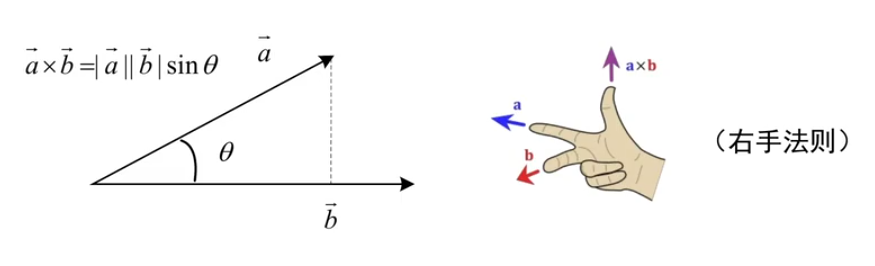
叉乘的物理意义
其模长等于由 (boldsymbol{a}, boldsymbol{b}) 围成的平行四边形面积,模长的证明思路为:
[|boldsymbol{a} times boldsymbol{b}|^{2} = (|boldsymbol{a}||boldsymbol{b}| sin theta)^{2} = (|boldsymbol{a}||boldsymbol{b}|)^{2} - (|boldsymbol{a}||boldsymbol{b}| cos theta)^{2} = (|boldsymbol{a}||boldsymbol{b}|)^{2} - (boldsymbol{a} cdot boldsymbol{b})^{2} ]
叉乘的一些性质
Hadamard 积(逐元素乘积)
若矩阵 (boldsymbol{A}) 和 (boldsymbol{B}) 同型,Hadamard 积等于它们各位置元素对应相乘得到的新矩阵,记作 (boldsymbol{A} odot boldsymbol{B}):
[boldsymbol{A}=left(begin{array}{ccc} a_{11} & cdots & a_{1 n} \ vdots & ddots & vdots \ a_{m 1} & cdots & a_{m n} end{array}right), boldsymbol{B}=left(begin{array}{ccc} b_{11} & cdots & b_{1 n} \ vdots & ddots & vdots \ b_{m 1} & cdots & b_{m n} end{array}right), quad boldsymbol{A} odot boldsymbol{B}=left(begin{array}{ccc} a_{11} b_{11} & cdots & a_{1 n} b_{1 n} \ vdots & ddots & vdots \ a_{m 1} b_{m 1} & cdots & a_{m n} b_{m n} end{array}right) ]
【注】Hadamard积也称为Schur积。
Kronecker 积(克罗内克积)
设有 (boldsymbol{A}_{m times n}) 和 (boldsymbol{B}_{p times q}),Kronecker 积表示用 (boldsymbol{A}) 中任意元素 (a_{ij}) 乘以 (boldsymbol{B}) 后扩张得到的 (mp times nq) 型矩阵,记作 (boldsymbol{A} otimes boldsymbol{B}):
示例:若
[boldsymbol{A} = begin{pmatrix} a_{11} & a_{12} & a_{13} \ a_{21} & a_{22} & a_{23} end{pmatrix}, quad boldsymbol{B} = begin{pmatrix} b_{11} & b_{12} \ b_{21} & b_{22} end{pmatrix}, ]
则 Kronecker 积为:
[boldsymbol{A} otimes boldsymbol{B} = begin{pmatrix} a_{11}boldsymbol{B} & a_{12}boldsymbol{B} & a_{13}boldsymbol{B} \ a_{21}boldsymbol{B} & a_{22}boldsymbol{B} & a_{23}boldsymbol{B} end{pmatrix} = begin{pmatrix} a_{11}b_{11} & a_{11}b_{12} & a_{12}b_{11} & a_{12}b_{12} & a_{13}b_{11} & a_{13}b_{12} \ a_{11}b_{21} & a_{11}b_{22} & a_{12}b_{21} & a_{12}b_{22} & a_{13}b_{21} & a_{13}b_{22} \ a_{21}b_{11} & a_{21}b_{12} & a_{22}b_{11} & a_{22}b_{12} & a_{23}b_{11} & a_{23}b_{12} \ a_{21}b_{21} & a_{21}b_{22} & a_{22}b_{21} & a_{22}b_{22} & a_{23}b_{21} & a_{23}b_{22} end{pmatrix} ]
【注】两个向量的叉乘积就是两个向量的Kronecker 积。
用矩阵(boldsymbol{A})的每个子矩阵与矩阵(boldsymbol{B})对应做Hadamard积并求和,将所有结果排列成一个新矩阵就称为卷积矩阵,其中(boldsymbol{B})是卷积核(Kernel)。卷积定义中比较关键的参数有三个:kernel_size,stride,padding
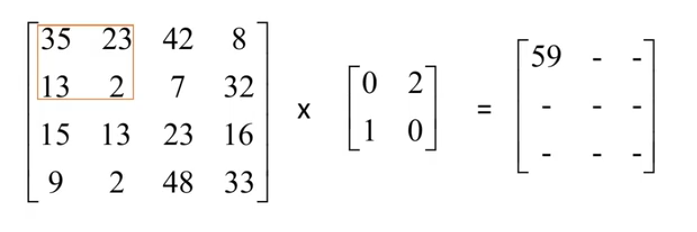
上图中经过卷积运算后的矩阵的第一行第一列元素59的来源:取(boldsymbol{A})的子矩阵(begin{bmatrix}
35 & 23\
13 & 2
end{bmatrix})与(boldsymbol{B})做Hadamard积,即(begin{bmatrix}
35 & 23\
13 & 2
end{bmatrix}odotbegin{bmatrix}
0 & 2\
1 & 0
end{bmatrix}=begin{bmatrix}
35times 0 & 23 times 2\
13times 1 & 2times 0
end{bmatrix}=begin{bmatrix}
0 & 46\
13 & 0
end{bmatrix}),然后对此矩阵的所有元素求和得(0+46+13+0=59).
【注】我们在此处定义得卷积是在深度学习中的卷积,实际上,卷积的定义是:
设有两个连续函数(f(x),g(x)),它们卷积的标准定义是((f * g)(x)=int f(t) g(x-t) mathrm{d} t),注意卷积和内积定义的区别,两个函数内积的定义是(
kernel_size是卷积核矩阵的大小,比如(3times 3);
stride是卷积核一次滑动的步长,滑动卷积核时,我们会先从输入的左上角开始,每次往左滑动一列或者往下滑动一行逐一计算输出,我们将每次滑动的行数和列数称为Stride,即步长,在下图中,Stride=2。

填充(padding)是指在输入高和宽的两侧填充元素(通常是0元素)。padding的值表示填充多少层0,比如下图中padding为1,说明是在矩阵外层填一层0再运算。

卷积就是这样按照刚才的三个参数逐层滑动对矩阵进行计算 ,卷积运算不仅对矩阵有用,对张量同样有效。
【补】彩色图像在计算机中的存储原理:从数学矩阵视角看:
RGB像素的数学表示
彩色图像的每个像素由红(R)、绿(G)、蓝(B)三种颜色混合而成,数学上可表示为一个3维列向量:
$ text{像素} = begin{pmatrix} R G B end{pmatrix} $
其中 $ R, G, B $ 是取值在0到255之间的整数(如 $ R=255 $ 表示纯红色,$ R=0 $ 表示无红色)。
图像的矩阵与三维结构
一幅分辨率为 $ H times W $ 的彩色图像,在计算机中本质是一个“三维矩阵”,可理解为“由多个二维矩阵堆叠而成”:
具体例子(以2×2彩色图像为例):
假设一幅2×2的图像包含4个像素,其数学表示为:
$
text{图像} = begin{pmatrix}
begin{pmatrix} 255 0 0 end{pmatrix} & begin{pmatrix} 0 255 0 end{pmatrix}
begin{pmatrix} 0 0 255 end{pmatrix} & begin{pmatrix} 255 255 0 end{pmatrix}
end{pmatrix}
$
三维矩阵(3阶张量)的“通道”概念
上述矩阵可拆解为3个二维矩阵(分别对应R、G、B通道):
数值的数学含义
通道顺序的数学差异
通俗总结:彩色图像在计算机里就像“三层叠在一起的数字表格”,每层表格记录一种颜色的深浅(用0-255的数字表示),三层合起来就是我们看到的彩色画面。这种结构在数学上对应三维矩阵,为图像的数学运算(如图像变换、深度学习卷积)提供了基础。

上图是一些特殊的卷积核对图像做的一些处理。
【AI解释什么是卷积】用通俗语言解释卷积的 “反向滑动” 本质
一、先看一个离散的 “乘法求和” 类比(类比线性代数中的向量运算)
假设我们有两个数组:
- 数组
f = [f1, f2, f3]- 数组
g = [g1, g2, g3]内积(点积) 的计算是:
f·g = f1*g1 + f2*g2 + f3*g3
本质:对应位置直接相乘再相加,没有 “位置移动” 的过程。卷积 的计算呢?我们先看离散形式的定义(假设数组长度有限):
(f * g)[x] = f1*g[x-1] + f2*g[x-2] + f3*g[x-3]
这里的x表示 “滑动到的位置”,但关键是:g 的下标是x-t(t 是 f 的下标),这相当于把 g 数组 “倒过来” 后再滑动。举个具体例子,计算
f和g的卷积:
先把 g 数组反转:原 g 是
[g1, g2, g3],反转后是[g3, g2, g1];然后让反转后的 g 从左到右滑过 f
,每次滑动时,对齐的位置相乘再相加:
- 滑动到位置 1:
f1*g3(只有一个元素重叠);- 滑动到位置 2:
f1*g2 + f2*g3;- 滑动到位置 3:
f1*g1 + f2*g2 + f3*g3;- 滑动到位置 4:
f2*g1 + f3*g2;- 滑动到位置 5:
f3*g1。发现了吗? 卷积的 “反向” 来自于对其中一个数组的反转,而 “滑动” 是反转后沿着另一个数组移动的过程。
二、用高等数学的积分思维理解连续函数的卷积
连续函数的卷积定义是
(f * g)(x) = ∫ f(t)g(x-t)dt,可以拆成两步理解:
- 把函数 g “关于 t 轴反转”:从
g(t)变成g(-t),这一步是 “反向” 的核心;- 把反转后的 g 沿着 x 轴 “滑动 t 个单位”:变成
g(x-t),这里的x就是滑动到的位置,t是积分变量(相当于遍历所有可能的重叠位置)。类比高等数学中的 “叠加求和”:
- 内积
∫f(x)g(x)dx相当于 “f 和 g 在每个 x 处直接相乘后求总面积”;- 卷积
∫f(t)g(x-t)dt相当于 “先把 g 反转,再滑到 x 位置,然后计算 f (t) 和 g (x-t) 在所有 t 处的乘积面积”—— 这里的g(x-t)相当于 “反转后的 g 滑到 x 时,在 t 处的取值”。三、为什么卷积要 “反向滑动”?—— 从 “加权叠加” 的意义理解
假设
f是 “信号”,g是 “滤波器”:
- 内积是 “信号和滤波器在同一位置的匹配度”;
- 卷积是 “用反转后的滤波器去‘扫描’信号,每个位置 x 的结果表示:信号 f 在过去各个时刻 t 的取值,被滤波器 g 在 (x-t) 时刻的‘权重’加权后的总和”。
比如:
- 当 x=5 时,
g(5-t)表示 “在当前时刻 5,滤波器对 t 时刻的信号赋予的权重”,t 越小(越接近过去),权重对应的是反转后 g 的右侧元素。- 这就像用一个 “反转的滤镜” 从左到右扫描信号,每个位置的结果都是信号历史值的加权和,而 “反转” 是为了让滤镜的 “先后顺序” 与信号的时间顺序一致。
四、深度学习中的 “卷积” 为什么感觉没反向?
深度学习中的 “卷积” 本质是互相关(cross-correlation),即直接用 g 滑动而不反转(公式是
∫f(t)g(x+t)dt或类似形式)。这是因为:
- 深度学习中 g(卷积核)是可学习的参数,反转与否可以通过参数学习自动调整;
- 实际应用中,“滑动” 的过程更直观,而 “反向” 被隐含在参数初始化或学习过程中。
但从数学定义上,标准卷积的反向滑动是其本质特征,只是深度学习中为了简化计算和理解,常使用互相关作为近似(效果上等价于 “学习一个反转后的卷积核”)。
一句话总结:
卷积的反向滑动,本质是让两个函数在 “时间” 或 “空间” 上的作用顺序相反 —— 一个函数的当前位置,对应另一个函数的 “历史位置”,通过反转和滑动,实现对 “过去信息” 的加权叠加。
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部