这篇文章与ICML2022的Open-sampling是同一个作者,方法一模一样,只是问题的场景变为噪声标签学习,Open-sampling是长尾问题的场景,可参见写的这篇blog。
这两篇文章大致做法完全相同:对biased数据集引入开集数据,在每个epoch分配均匀的闭集标签。如果是long tailed data,还涉及不平衡问题,因此分配就不是均匀分布了(详见之前的blog)。而这篇文章比Open-sampling早,且是在噪声标签学习问题上进行的,因此对于开集样本标签分配只是简单的均匀分配。但这篇文章提供了解释:为什么引入开集样本能帮助biased数据学习?

对于无标签的数据集(mathcal{D}_{out}),每个epoch会生成新的服从均匀分布的闭集噪声标签(mathcal{U}_k),这部分数据使用单独的损失函数计算损失:
[mathcal{L}_2=mathbb{E}_{mathcal{D}_{mathrm{out}}}left[ellleft(f(widetilde{boldsymbol{x}};boldsymbol{theta}),widetilde{y}right)right]=mathbb{E}_{mathcal{D}_{mathrm{out}}}left[-e^{widetilde{y}}log fleft(widetilde{boldsymbol{x}};boldsymbol{theta}right)right],mathrm{where~}widetilde{y}simmathcal{U}_k ]
(f)表示分类器。而原来的数据集(mathcal{D}_{train})使用另外的损失函数,整体的训练目标为:
[mathcal{L}_{mathrm{total}}=mathcal{L}_1+etacdotmathcal{L}_2=mathbb{E}_{mathcal{D}_{mathrm{train}}}left[ellleft(f(x;boldsymbol{theta}),yright)right]+etacdotmathbb{E}_{mathcal{D}_{mathrm{out}}}left[ellleft(f(widetilde{x};boldsymbol{theta}),widetilde{y}right)right] ]
其中(eta)是一个超参数,用于平衡两个损失函数的重要性。(mathcal{L}_1)也可以使用其他的损失函数代替(文中使用的是CE)。
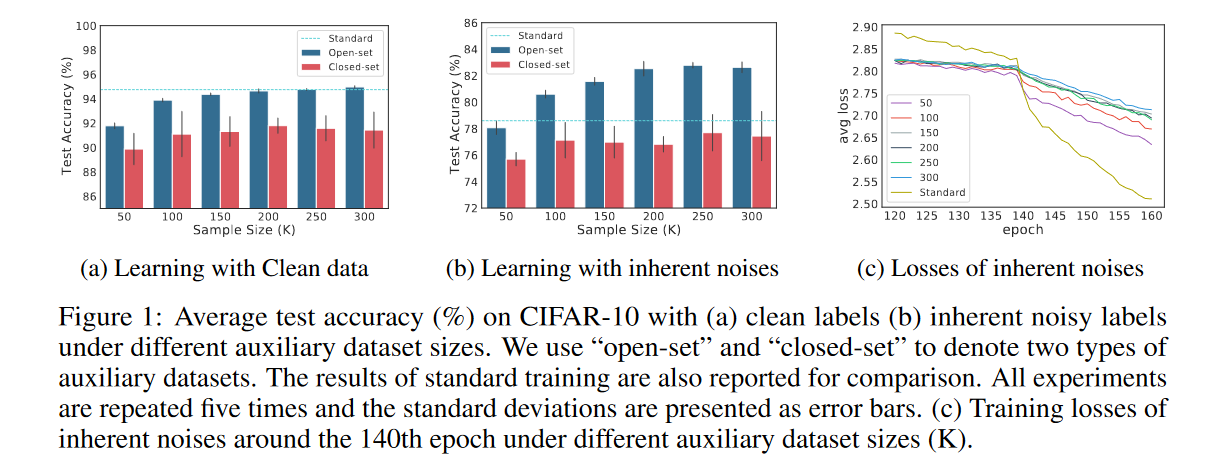
简单来说:利用open set,神经网络的额外容量可以在很大程度上消耗掉,而不会干扰对干净数据中学习。增加开集辅助样本的数量会减慢固有噪声的拟合(见Fig. 1c)。
站在SGD的角度,作者的方法引入的open set带来的噪声是随机方向的、无冲突的和偏置的,这可能有助于模型收敛到具有优异稳定性的平坦最小值,并强制模型对 open set产生保守的预测(作者还在OOD检测任务上进行了测试)。
作者在文中列举了关于噪声的SGD梯度相关证明,但个人觉得只是简单的化简。
噪声标签学习大概可以分为以下几点,但彼此间不独立,也可以相互结合,因此才有不少A+B的paper。
作者在文中仅考虑了与实例无关的开集噪声样本,大部分考虑训练集含开集噪声的论文也是如此。但实际场景下,开集噪声样本应当与干净样本有一定的相似性但仍不属于同一类(这在文中被称为instance-dependent open-set noisy labels),因此如果采用这种设置,结果可能又将不同。
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部