我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品。我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值。
本文作者:佳岚
AI 的大趋势: 24、25 年是 AI 应用大爆发的两年,随着 LLMs 越来越智能化,越来越多的应用实践被挖掘。
我们可以留意到我们使用的主流软件都或多或少集成了AI应用,如 Microsoft Edge 内置了 copilot,钉钉最近更新了AI助理,语雀、Notion 支持了 AI 帮写等等。
AI应用不光是在软件行业有着广泛应用,在游戏行业有着很大革新,例如:
同样的,在编程领域,AI 技术也为我们程序员的开发带来了很大的变革
作为程序员,我们在开发中往往会遇到以下问题:
选对的工具能让你事半功倍!
AI 编程工具的功能大致可以分为以下三个主要功能模块
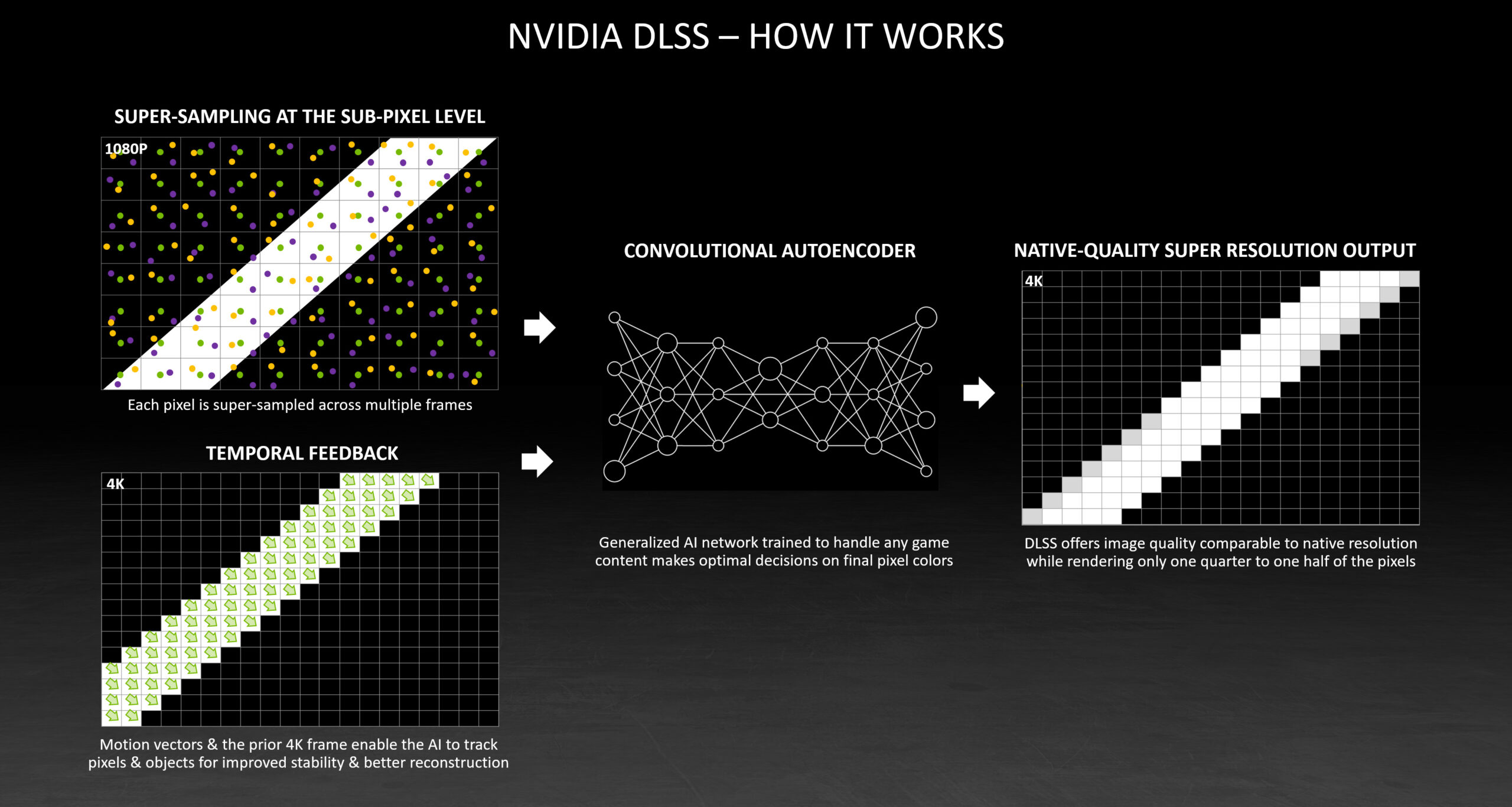
智能补全是 AI 编程开发中最先被发掘出也是最基础的功能。即在当前光标位置后通过行内补全的形式(灰色的代码块)提供后续可能的代码。

智能补全在实际开发中能极高的提高效率,它能够根据上下文信息来获取补全内容,不局限于以下上下文信息:
在进行重复代码编写或者具有上下文关联的代码编写时,具有 context-aware 能力的智能补全往往能带来不错的效率收益,并且不少工具会记忆最近的代码变更内容,让开发者感觉到越用越智能。
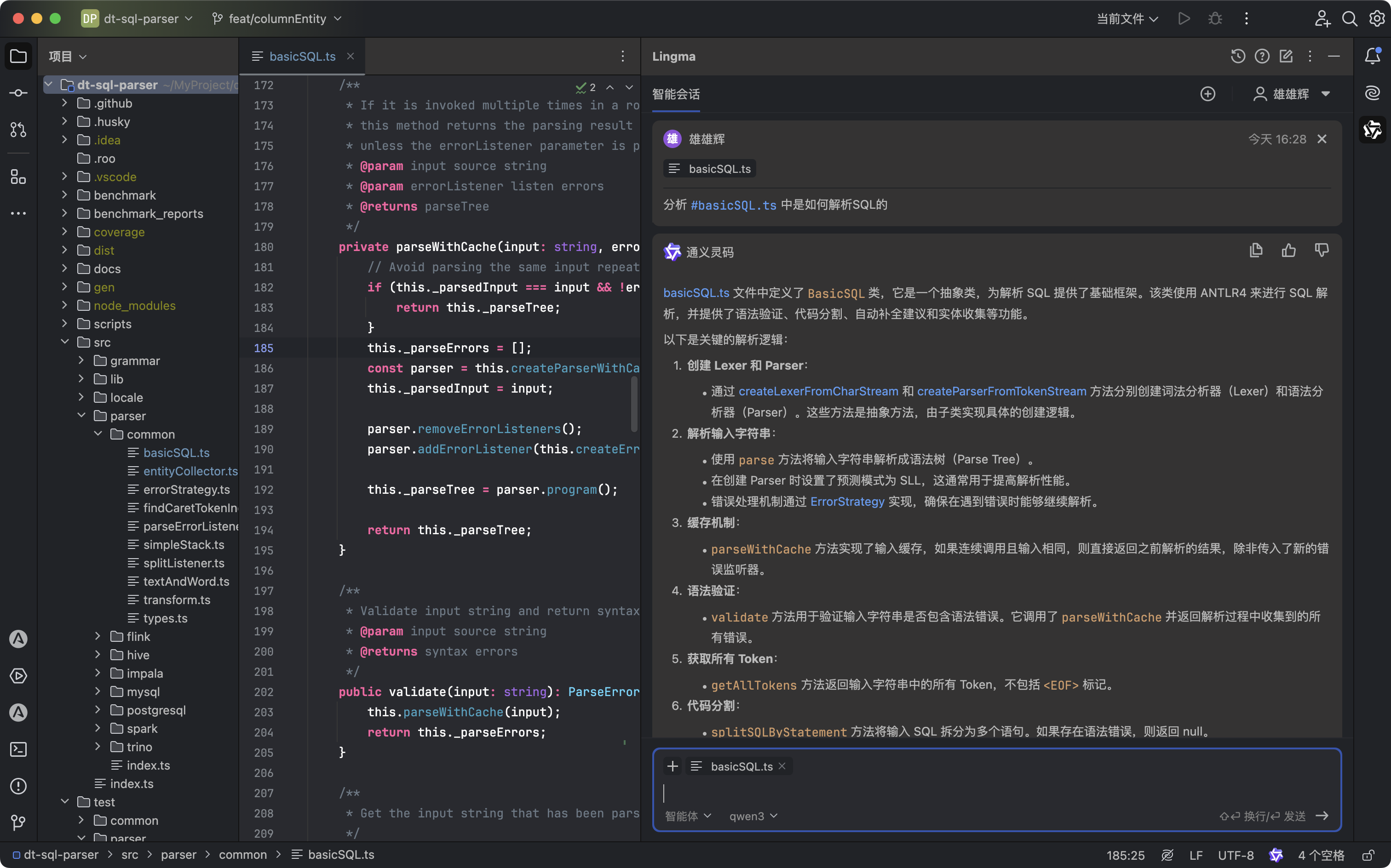
以我们的开源项目 dt-sql-parser 为例,每新增一种功能或者 bug 修复都要支持多种 SQL 语言,在补充单测时显得尤为枯燥与乏力,相似的工作做了N遍。基于智能补全的上下文感知,只需在一种语言中编写一次代码,在其他语言中就能直接一路 Tab 到位完成不同语言的单测编写。
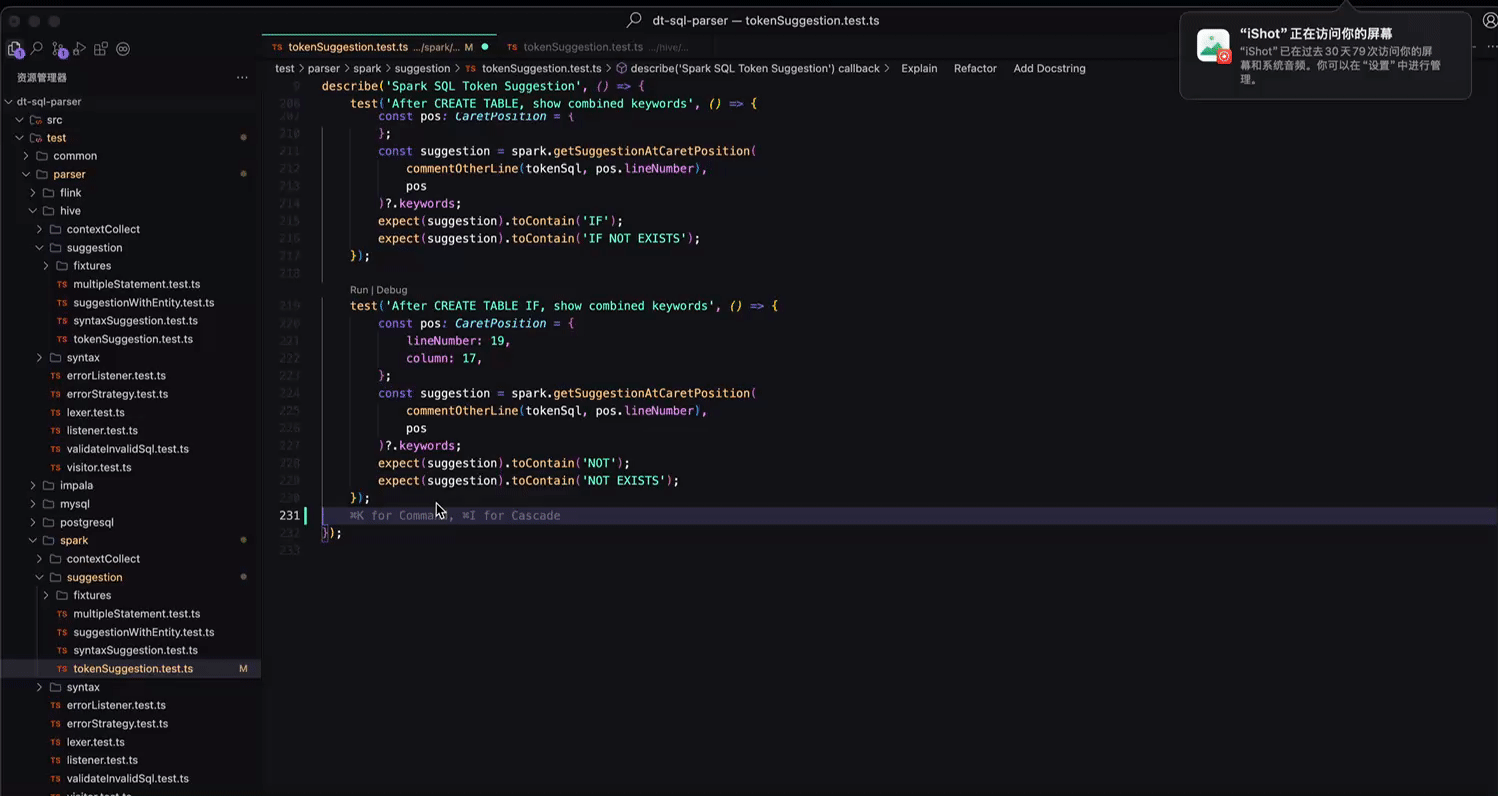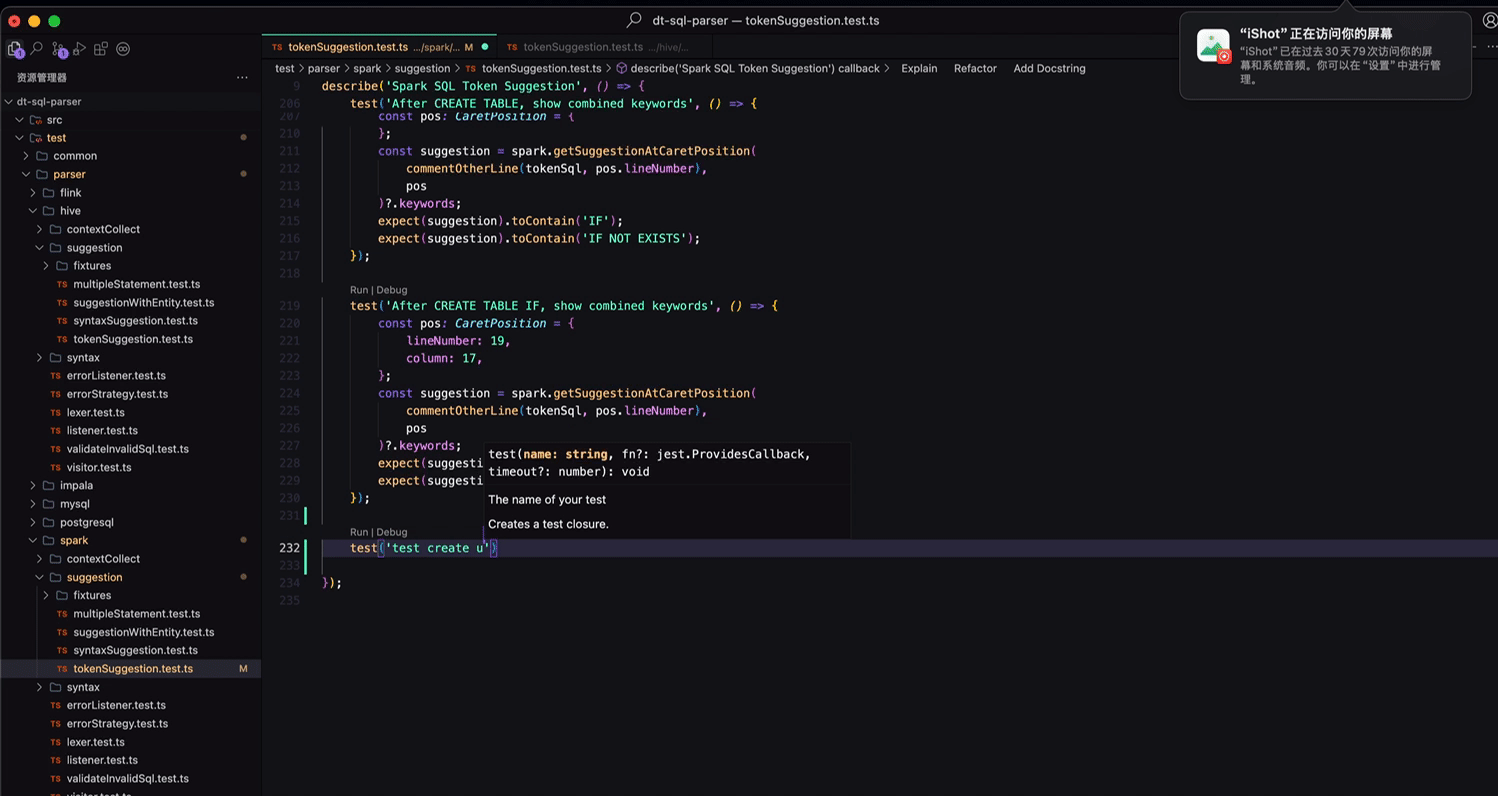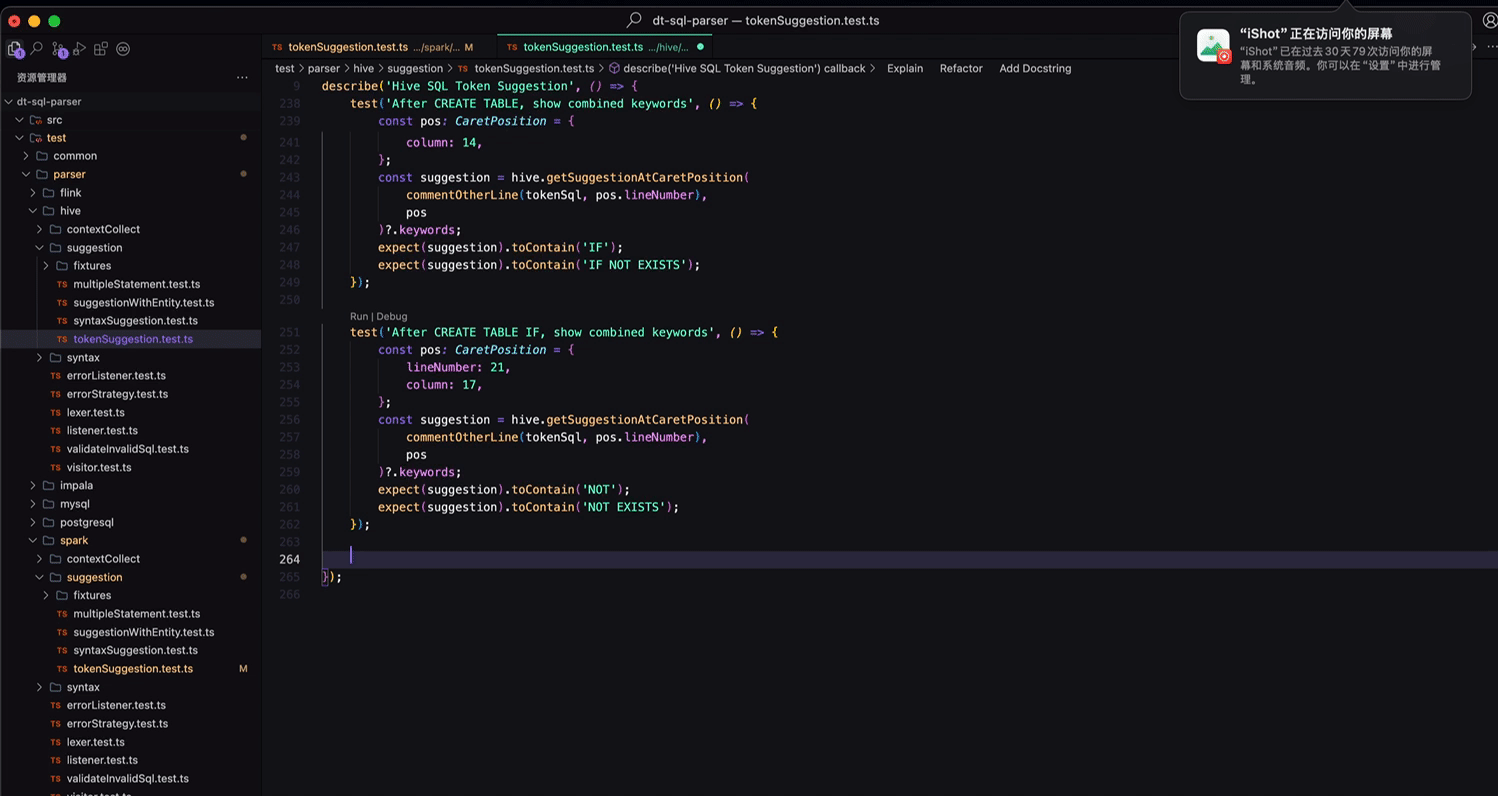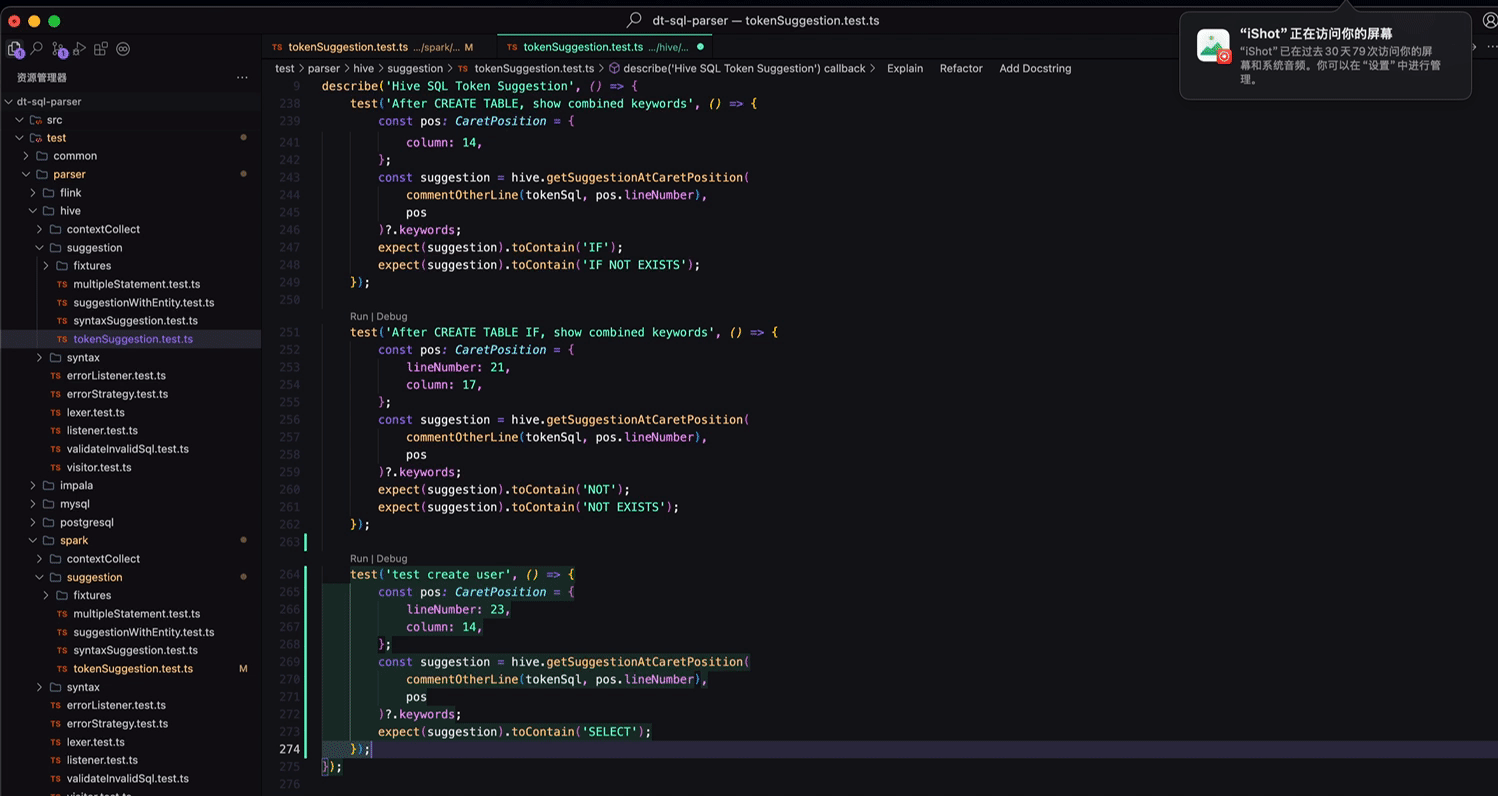
智能补全形态的进化
早期的智能补全只能补齐光标后面的内容(利用 inlineCompletion 实现的),而不能修改或者删除已有代码。为了打破这个限制,更多形态的智能补全被挖掘出来。
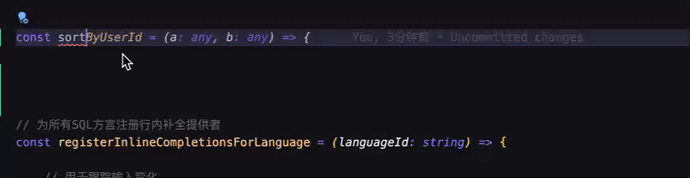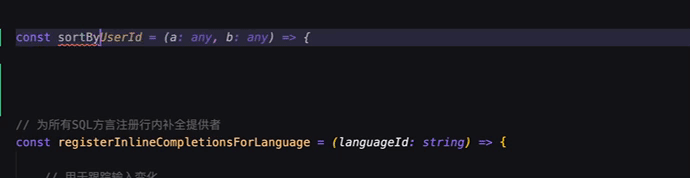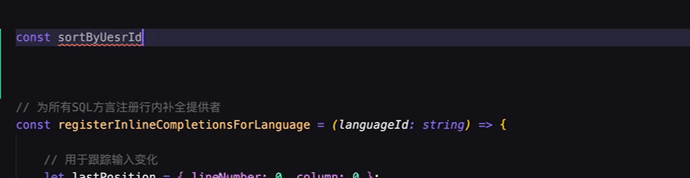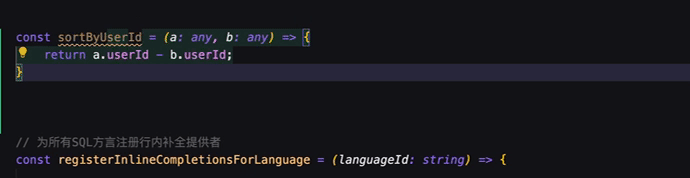

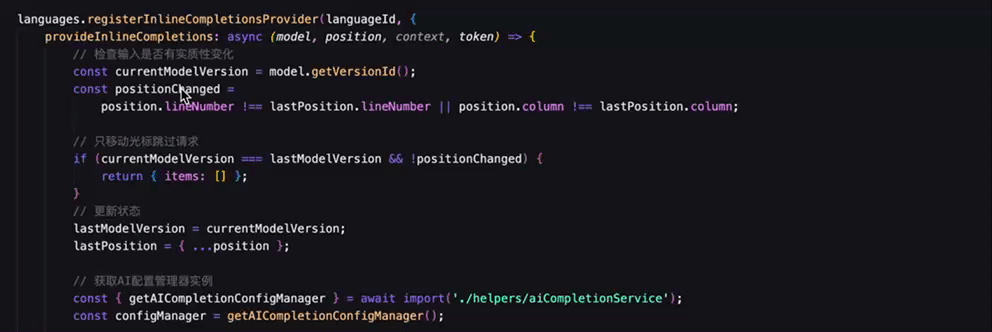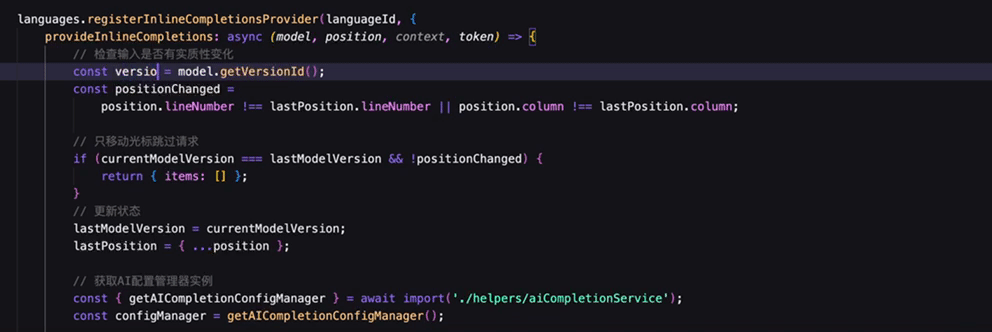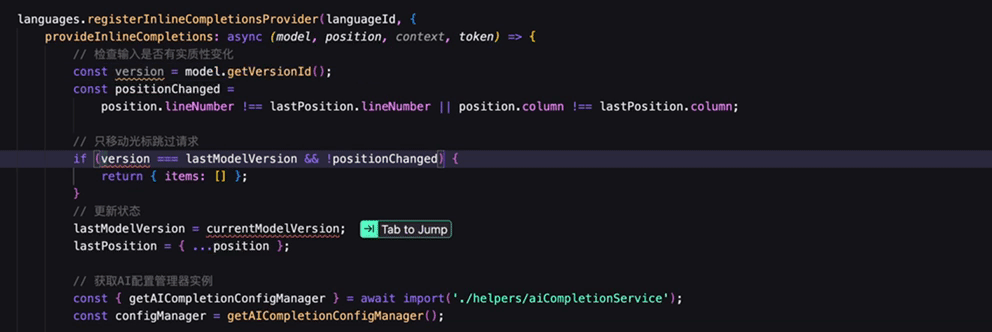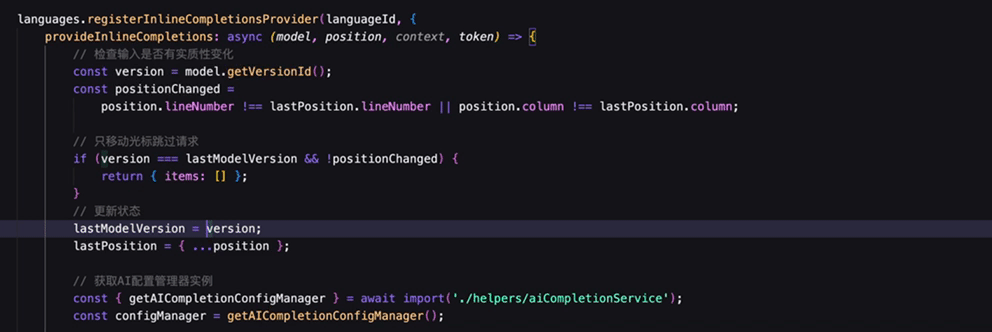
基于补、改、删、跳的交互的有机结合,智能补全已成为实际业务开发中最不可或缺的一部分。
直接在代码块中快速唤起一个弹窗以针对当前选中的代码进行修改, 提供轻量级的上下文,并且是没有对话记忆的,往往做一些非常明确的工作,如针对某个函数进行优化或者国际化翻译。

Chat 模式也是最开始被发掘的功能之一,相比网页端的大模型对话,Chat 模式可以快捷的提供上下文。
起初最传统的 Chat 模式的上下文需要手动引用,否则被传递的上下文非常有限,一般对话中只会将项目目录结构与当前打开的文件名作为上下文传递给大模型,常见支持的上下文引用如下:
在使用传统的 Chat 模式下,你会感觉到你需要过渡的引导大模型,大模型的最终输出效果与使用者手动提供的上下文有很大关系,且生成的代码也需要开发人员手动应用到对应位置。
在传统 Chat 模式下我们面临两个痛点:
Agent这个词我们经常听到,它的释义是"代理人",在编程领域指能够自主的分析、决策并执行的程序或系统。
在编程工具中的 Agent 模式非常强大,它能像人一样独自完成一系列任务而不需要人工的介入。
Agent 模式是如何做到的?
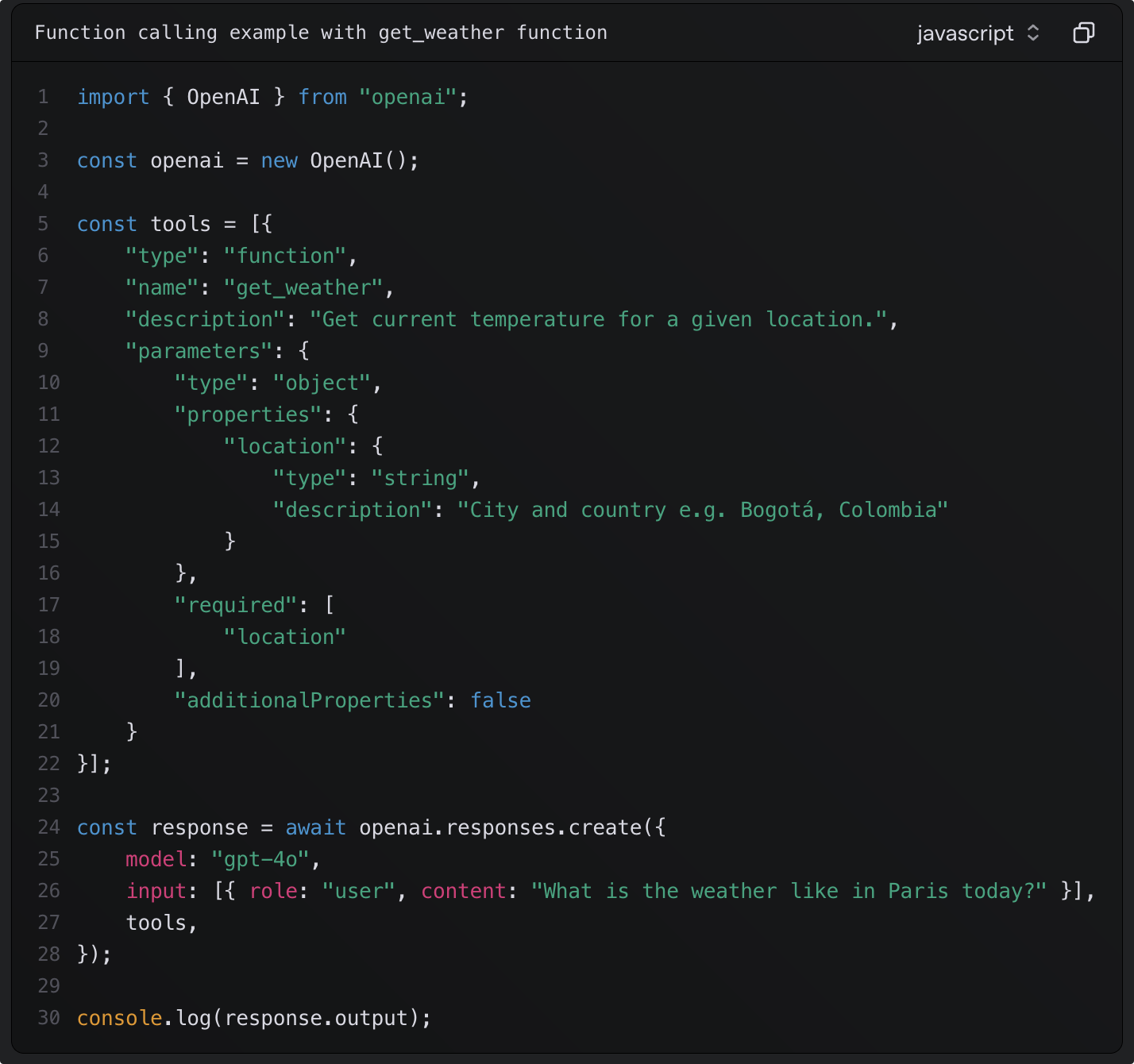
Agent 的实现本质上是建立在大模型的 function_call 或者 tools_call 的能力上的。
主流的大模型基本都支持工具调用,当客户端在调用大模型的 API 接口时,客户端侧定义一系列的内置工具,告诉大模型客户端能做到什么。
例如要我们自己实现 AI 编辑器的 Agent 模式,就需要定义大概以下工具:
在定义tools时需要详细的说明 description ,大模型会根据该字段信息并且经过意图识别后来决定调用哪个 tool
大模型识别到了意图并返回结构化消息, 以此与客户端进行交互。

Agent下的自我修正
自我修正能减少需要程序员的介入情况,例如 Agent 自主帮我们修改代码后,ts类型报错了或者产生了幻觉引用了不存在的方法,那么 Agent 在感知到报错信息后会自行去尝试修复,最终解决问题,整个流程中我们只需要做好一开始的提示词输入工作即可。

Codebase Indexing
全局代码库索引是一个非常重要的功能,它能实现语义化检索来帮助大模型获取整个代码库信息。
像 deepseek 上下文窗口大小只有 64k ,换算成代码行数大概时 2000-3000 行,将整个代码库作为上下文传递显然是不合理的,所以需要尽可能过滤出有用的代码信息。
与 RAG (检索增强生成) 技术相似,建立代码库索引大致分为以下步骤:
使用 codebase 前:
使用 codebase 后:
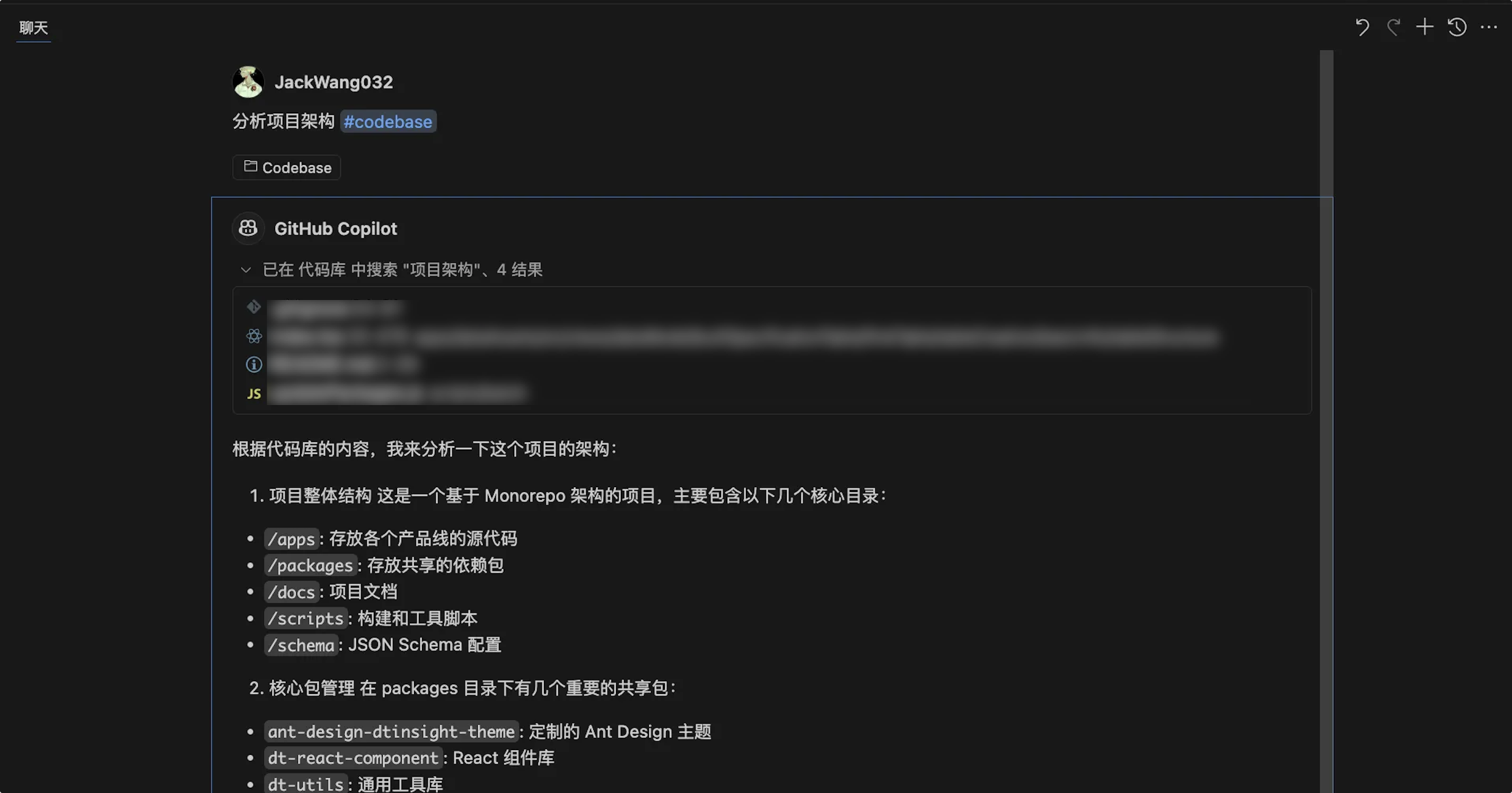
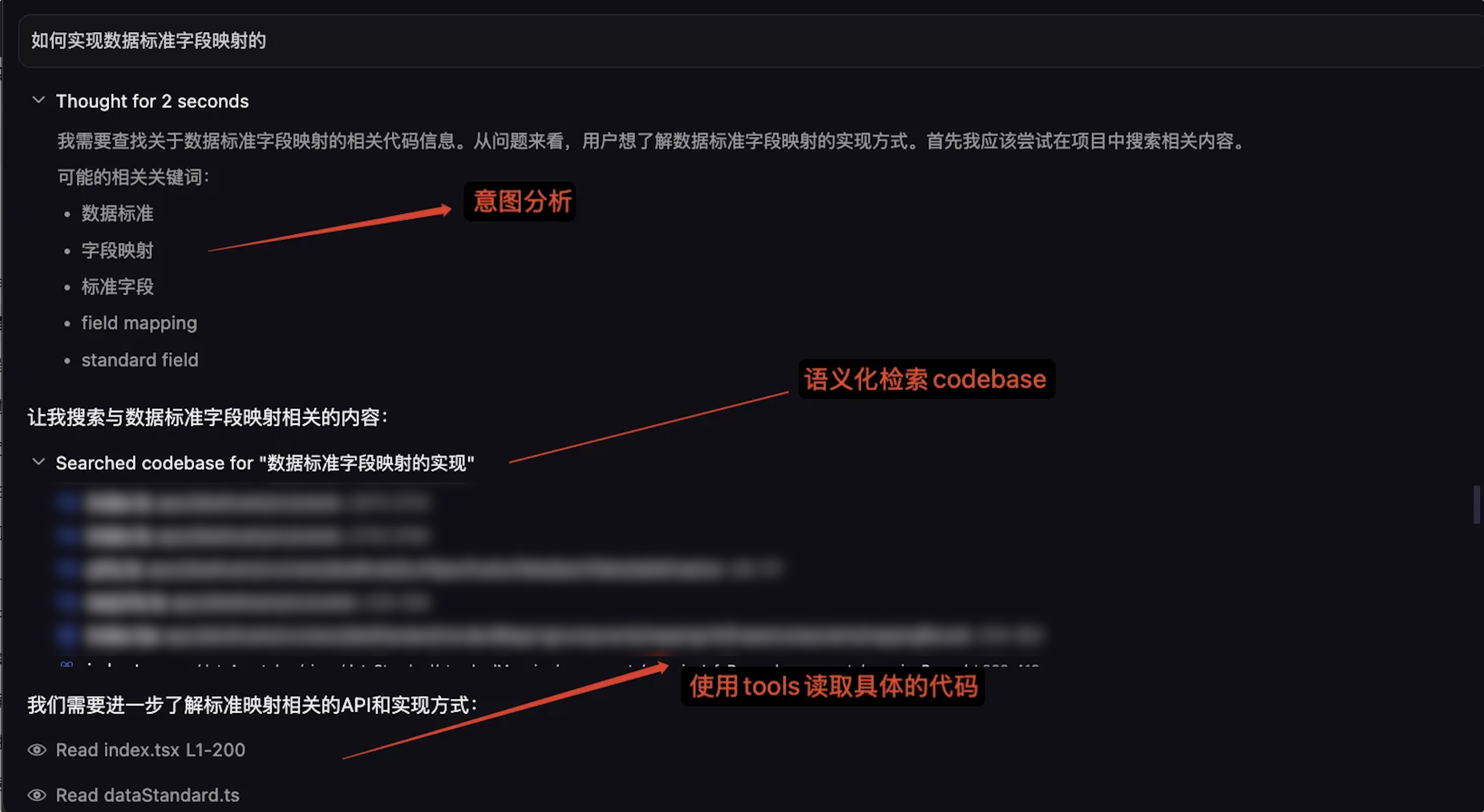
语义化检索以快速的定位到相关的文件:
:::info
Notice: 像 Cursor、Windsurf 等 IDE 已不需要在 Chat 模式下显式引用 @codebase 了, Chat 模式下也能做到自主的上下文感知。
:::
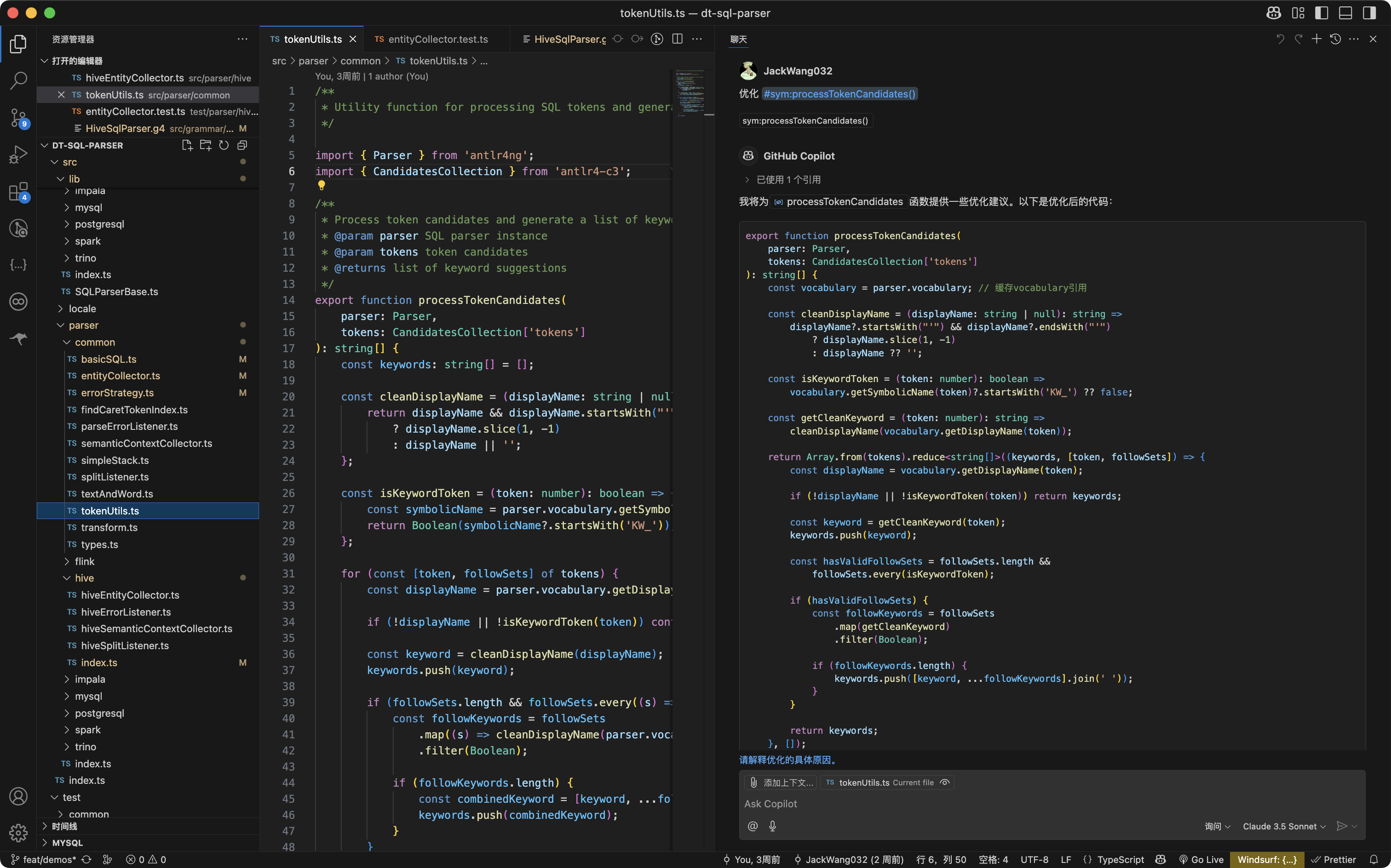
copilot 作为老大哥,已经内置进了 vscode 中,现在每次的 vscode 更新,都是大量针对 copilot 进行的迭代。但不可否认的是,copilot 现在已经落后于 cursor、windsurf。
另外我比较反感的是,copilot 的智能补全太懒惰,经常一次性只给你补全一行,并且速度相对较慢。

优点:
缺点:
拥有完全免费的智能补全功能, 支持几乎所有的智能补全形式, 补全的速度和质量非常理想
Cline 是一款开源的支持用户自定义 Agent 工作流的插件, 它实现了大模型与编辑器之间的交互流程,我们只需要提供大模型服务商的API地址,就能实现属于自己的 Agent。
Roo Code 是 Cline 的 fork 增强版本, 我们以 Roo Code 进行介绍。
使用 Roo Code 你可以接入本地部署的大模型以避免安全问题
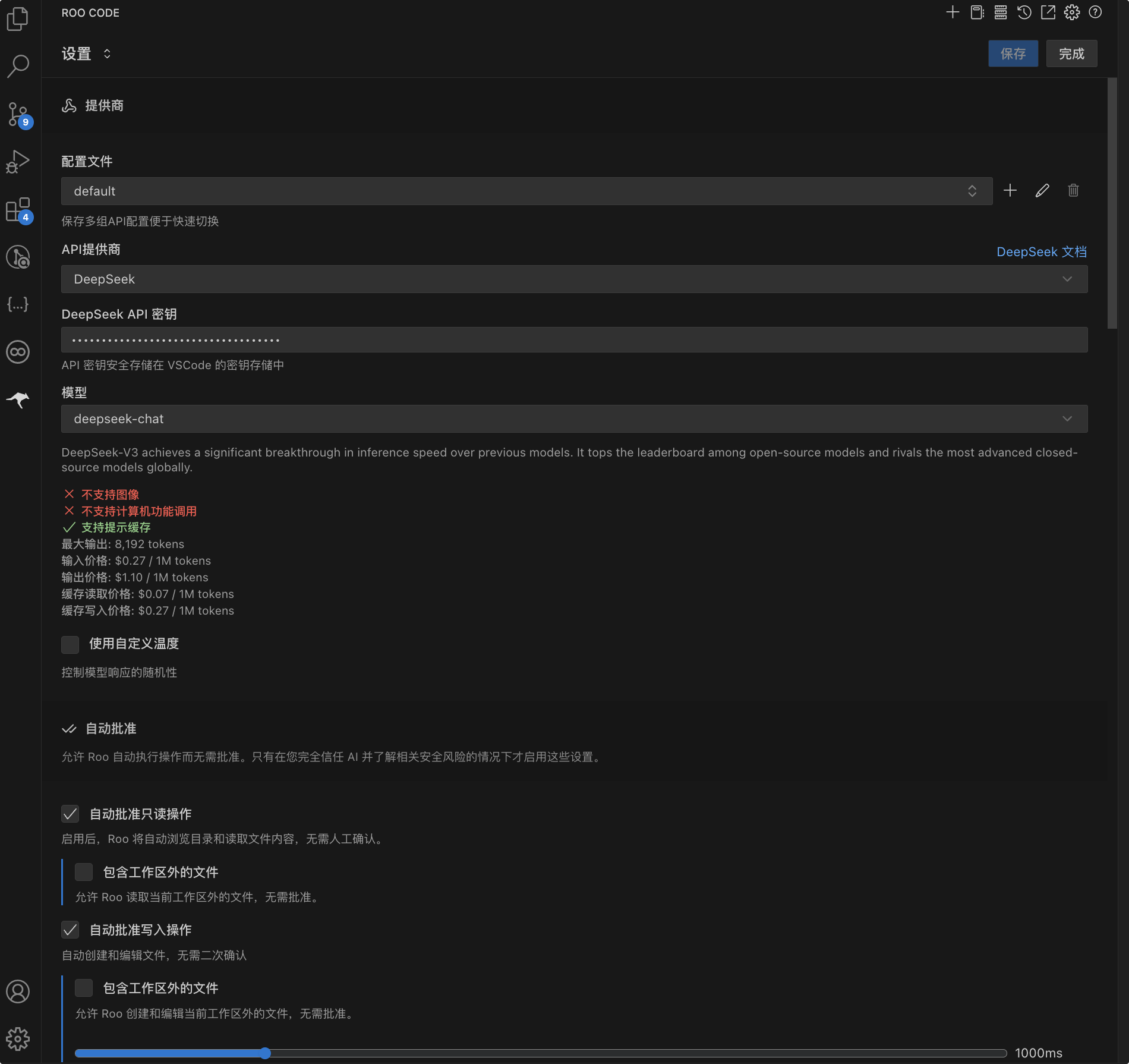
在 Roo Code 中,你可以自定义各种提示词,例如在问答模式下,允许大模型自主读取上下文,但不允许修改文件,你可以看到所有的系统提示词。
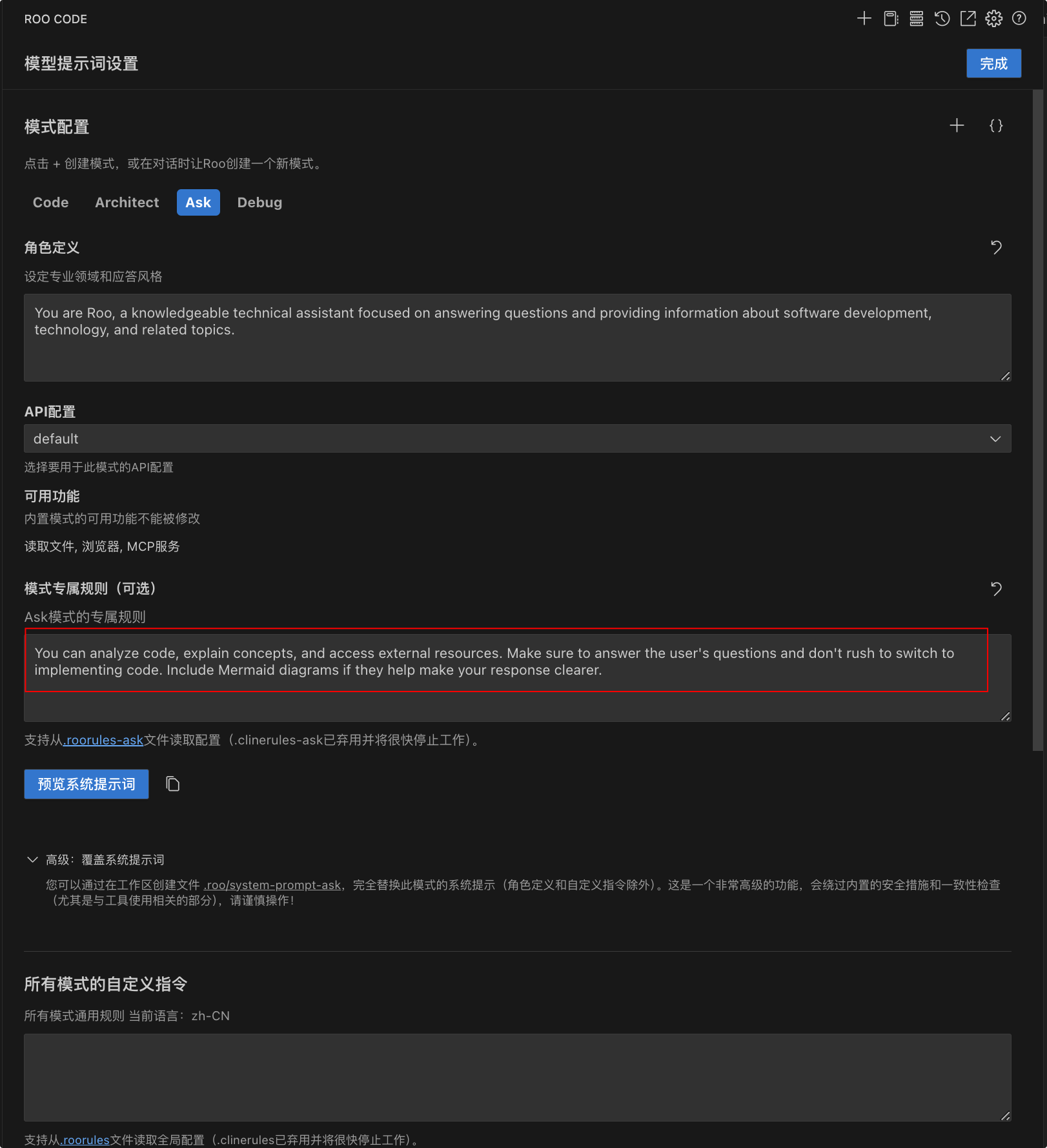
我们可以直接看到请求时携带的上下文信息,清晰的知道是如何与大模型交互的
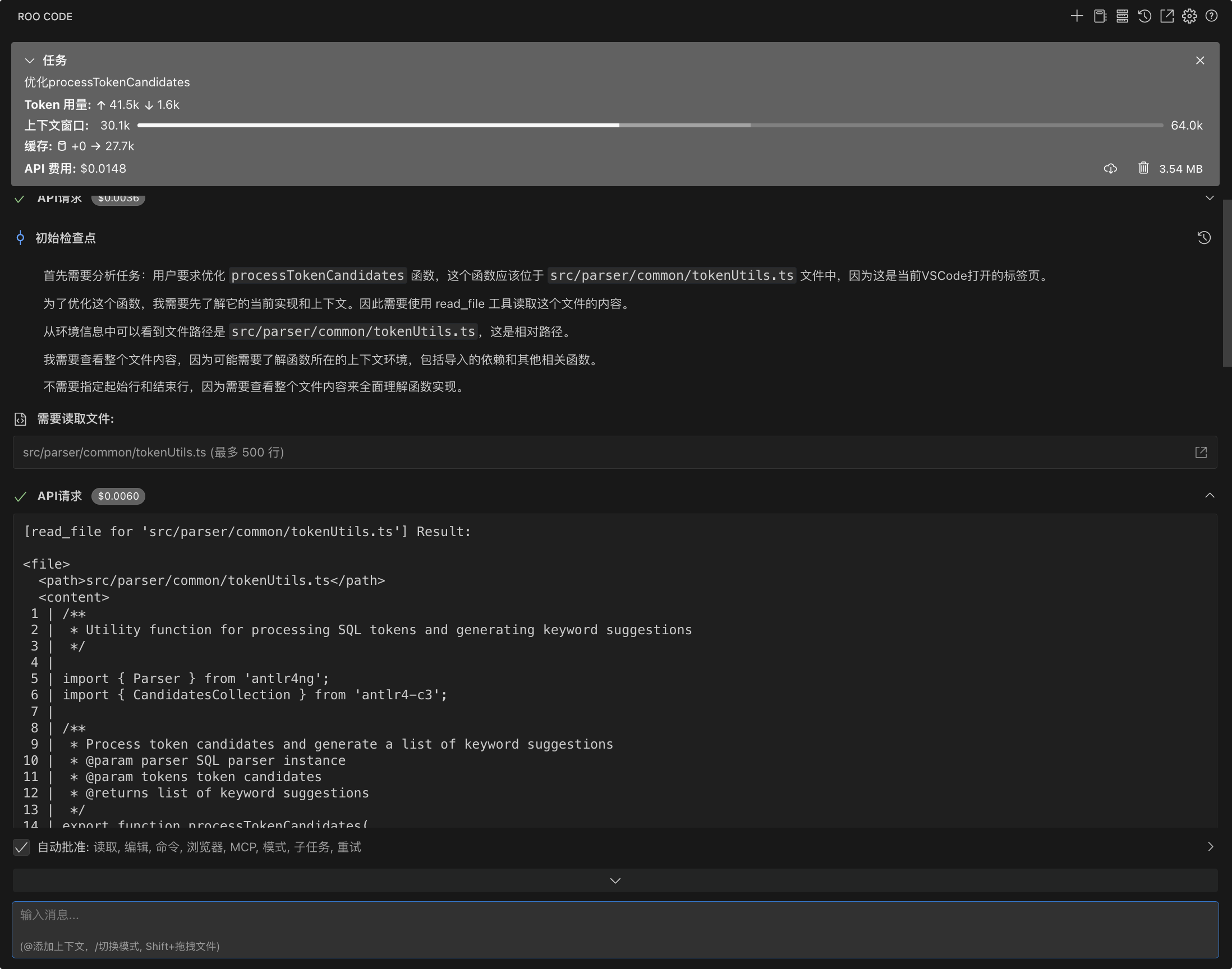
基于Roo Code我们可以很轻松的将 deepseek 集成进IDE中, 配合 Windsurf plugin 能够搭建一套自己的AI编程平台。
但是, Roo Code 对上下文大小优化比较有限,缺少对代码库索引的支持,没几次对话可能就超出上下文大小了。
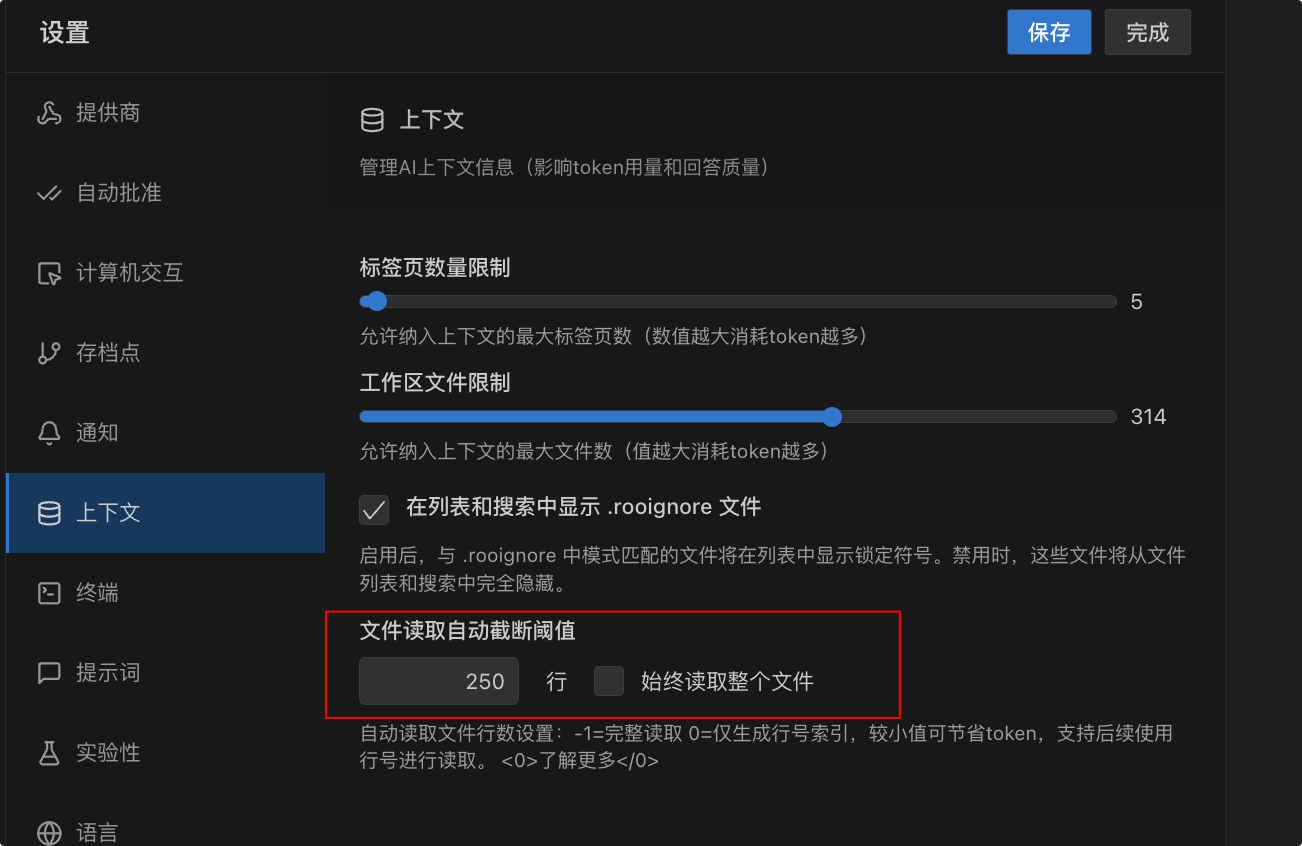
在中大型项目中,建议配置文件读取行数截断,否则会将整个文件的代码都传给大模型。
一般后端配合IDEA插件使用,前端使用比较少,不过多赘述。
Cursor, the world's best IDE.
作为最广为人知的AI IDE, 其综合体验下来像个五边形战士, 其拥有最好的 Agent 交互体验。
这体现在以下几个方面:

缺点:
Windsurf,Cursor 的最强竞品,基本上紧追着 Cursor 的步伐,功能迭代很频繁, 基本上该有的功能都有。
优点:
缺点:
Trae (The Real AI Engineer), 由字节开发的第一个国产 AI IDE ,基于 vscode , 内置 deepseek 和豆包,由于起步时间太晚,25年初才开启 beta 测试,很多功能还不成熟,还不足以当主力开发使用。
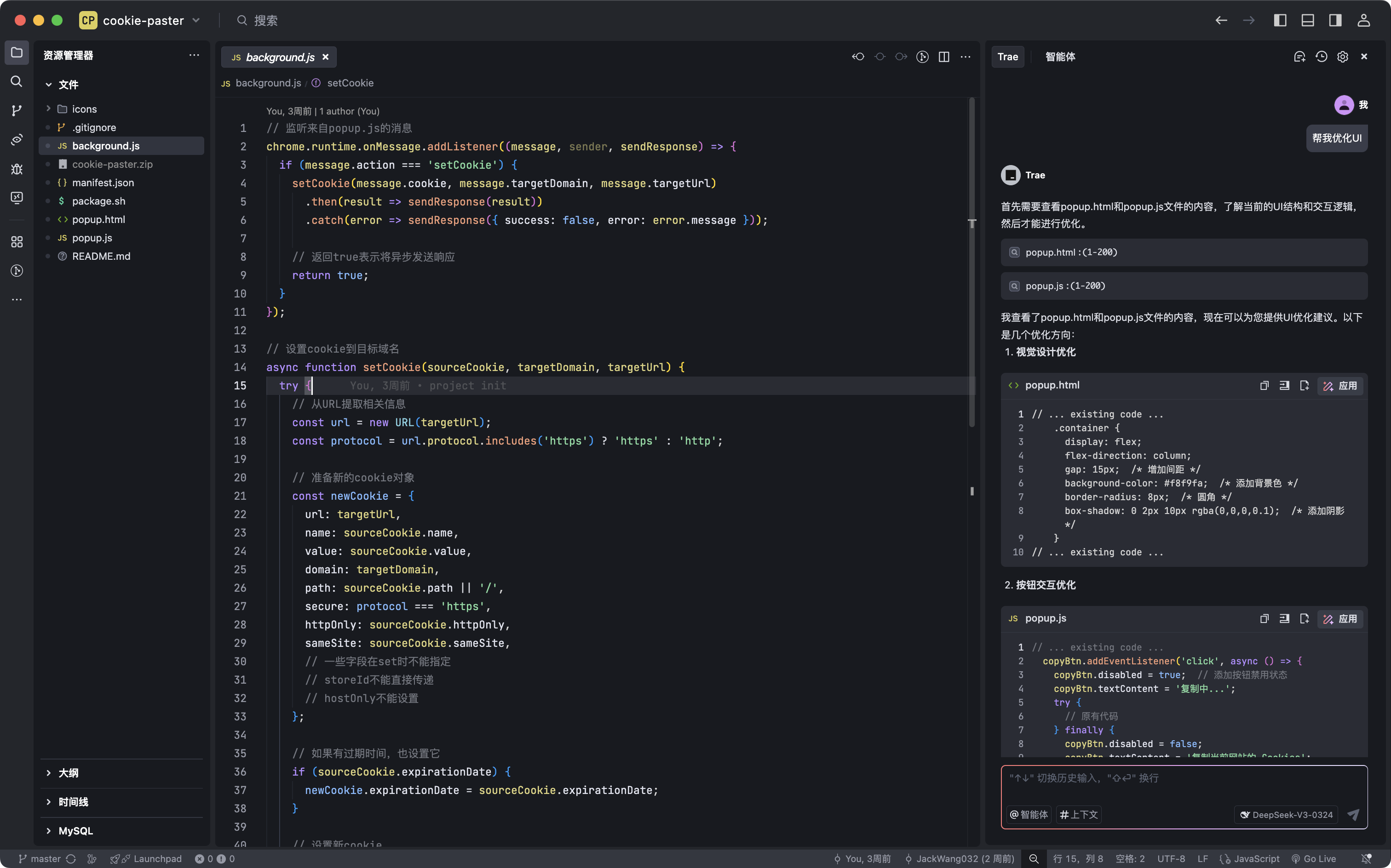
优点:
缺点:
:::info
:::
笔者在接近一年的实际使用体验下来,AI编辑器的集成度与交互体验是远胜于插件的,且目前三个主流 IDE 都是基于 vscode 的,可以直接无缝切换,强烈推荐直接使用 AI 编辑器作为主力开发工具。
此外,除 Cursor 与 Windsurf 外,智能建议 Widget 与行内智能补全共用了Tab快捷键,导致当有提供智能建议时,行内智能补全的前缀必须与当前建议列表所选择项的前缀一致才会展示,如下 vscode 中的表现:

而在Windsurf、Cursor中, Tab仅用于接受行内补全, 智能建议需要使用回车接受:
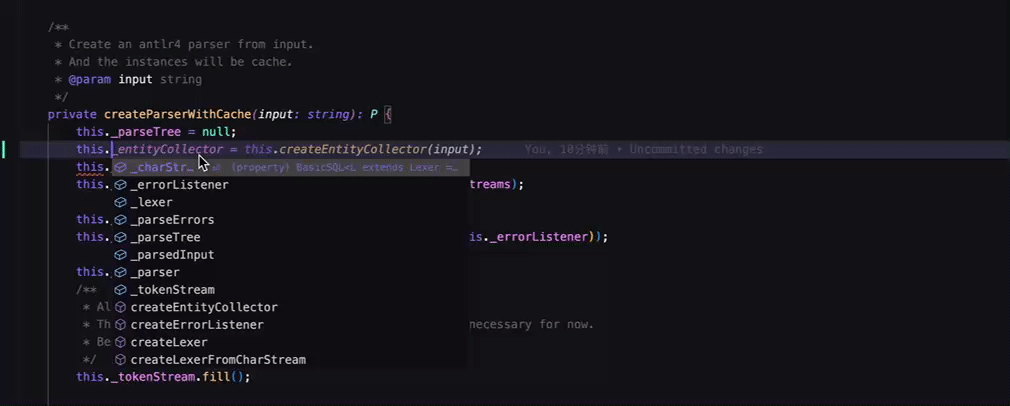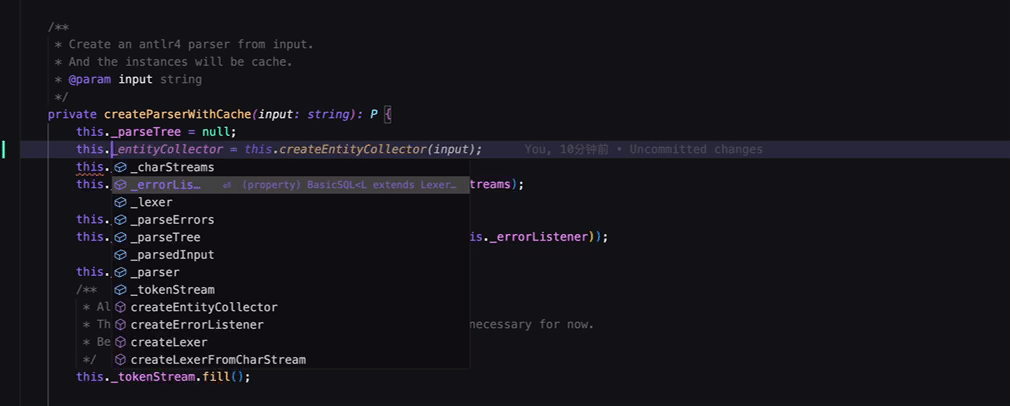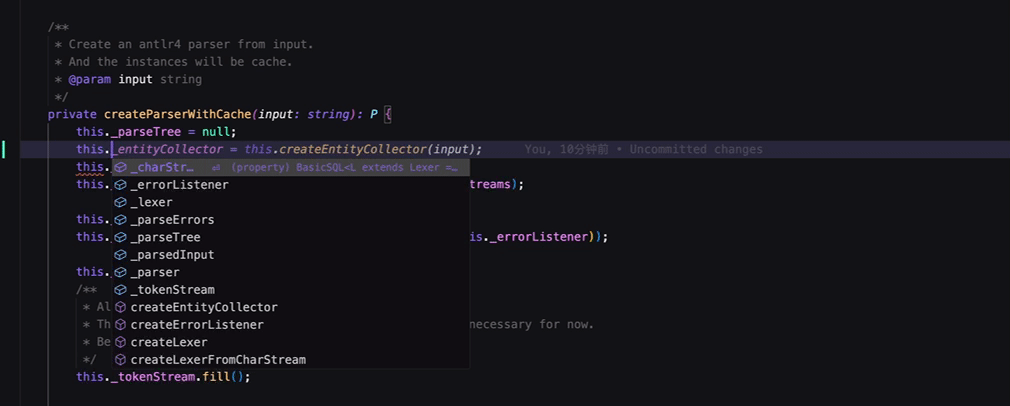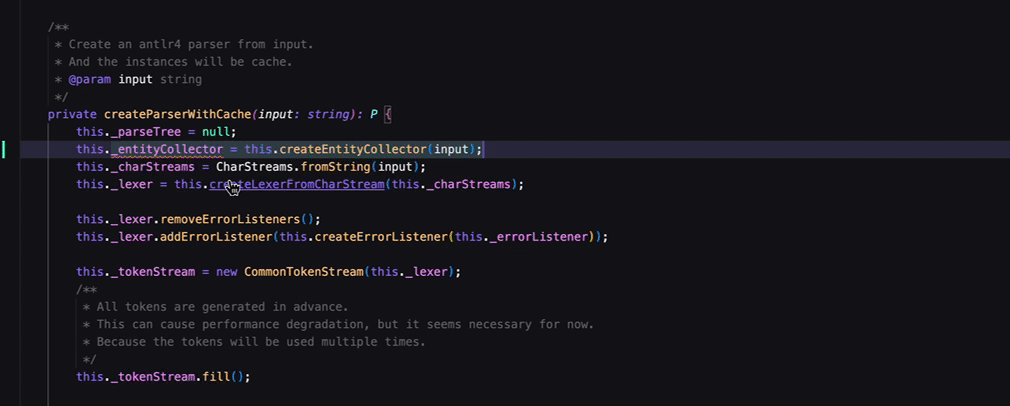
Windsurf、Cursor中的做法更好,智能补全触发会更及时与频繁。
如何选择一个正确的模型?
在使用 Agent 时,选择一个正确的模型往往能决定生成结果的好坏。
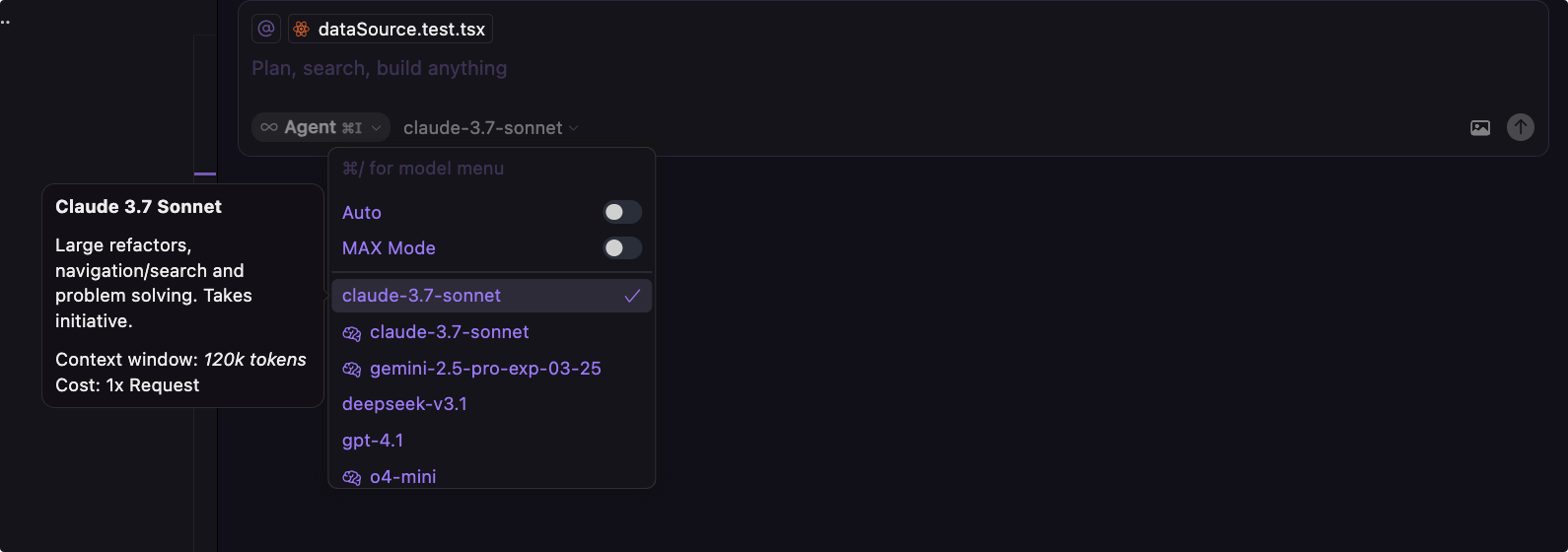
其实大多数情况下我们只需要按照自己的使用习惯来选择就好,这是我的使用习惯, 仅供参考:
| 优先级 | 模型名称 | 场景 |
|---|---|---|
| 第一优先 | claude-3.7(4.0)-sonnet | 绝大多数日常任务 |
| 第二优先 | claude-3.7(4.0)-sonnet-thinking | 复杂任务,从零开始设计或完成某个功能 |
| 第三优先 | gemini-2.5-pro-thinking | 当3.7-thingking的结果不理想时考虑使用 |
当然,你也可以参考 Cursor 的 Guide 中定义的一样,按照任务类型选择合适的模型

Rules 定义了大模型应该遵守的行为准则或可重复利用的上下文,如以什么语言回答用户,用什么风格的回答回应用户,Rules 会作为上下文在一开始对话时传递给大模型。
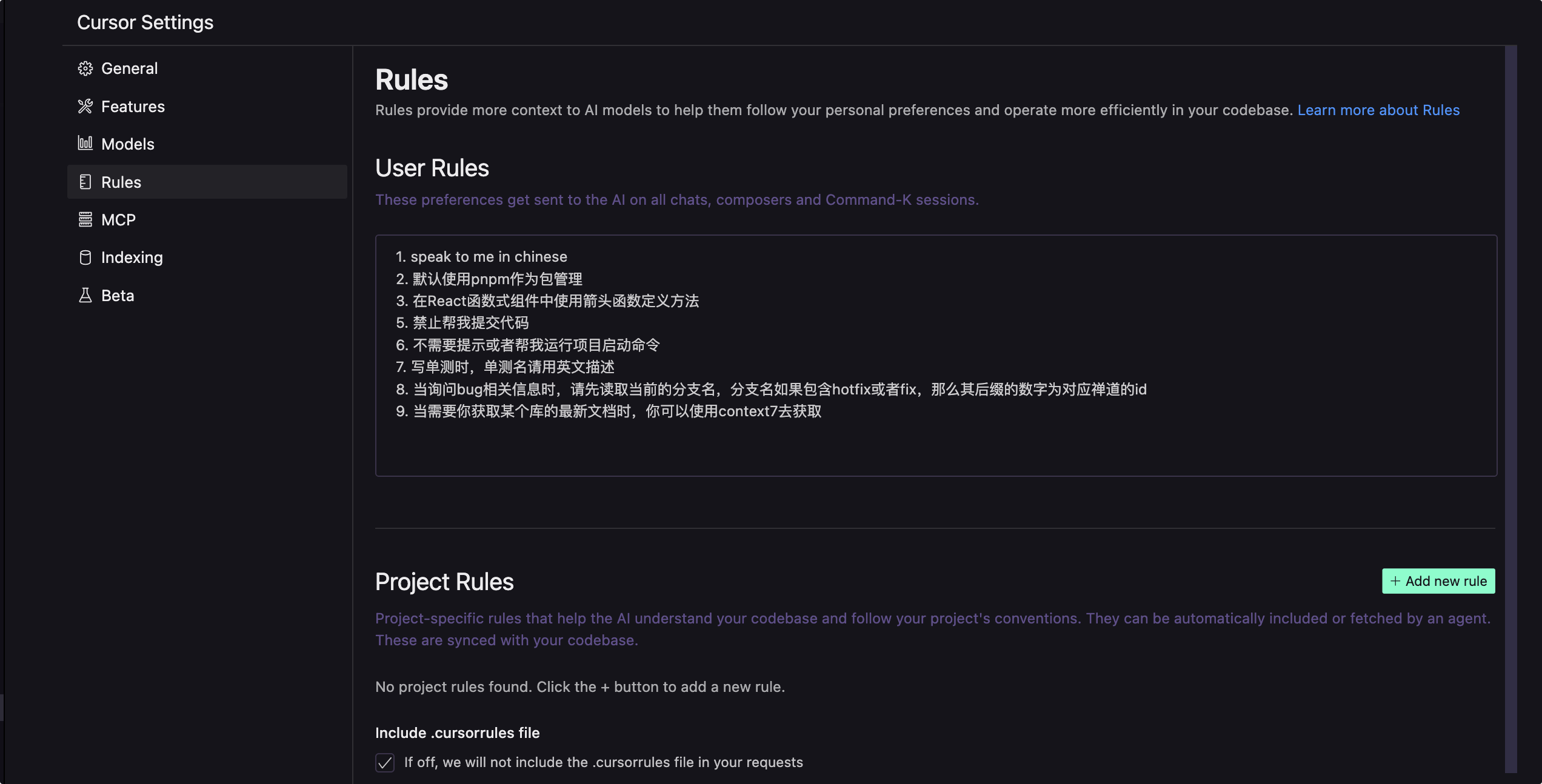
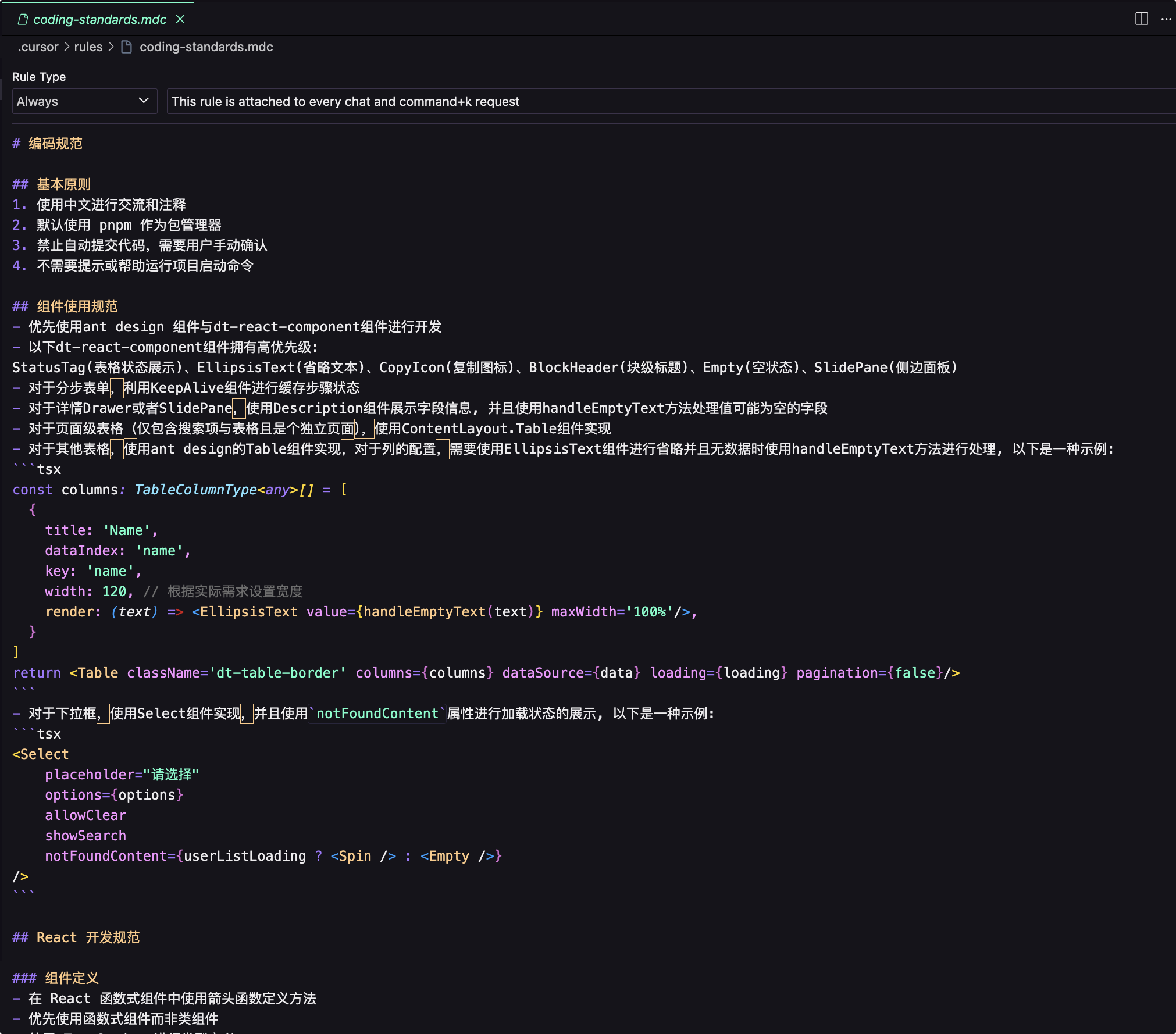
Rules 分为User Rules与项目Project Rules,在Project Rules中定义一些跟项目有关的编码规范,如:
@Past Chats引用其他对话的结果在业务开发中,往往需要提供更多的业务相关上下文,如数据表结构、内部业务文档等等信息,而利用MCP我们可以实现这些。
MCP (Model-Context-Protocal, 模型上下文协议), 主要用于扩展大模型的上下文获取能力。
它为何出现?
Cursor 等客户端提供了 read_file、list_directory 等内置 tools 使大模型能够意图识并调用这些 tools 以访问额外的上下文信息,但大模型所能获取上下文也仅限于 Cursor 提供的这些内置 tools,而 MCP 的出现使用户能自定义工具,让大模型能够做到任何事情,如连接数据库、操作浏览器、登录服务器获取日志等等。
MCP的架构:
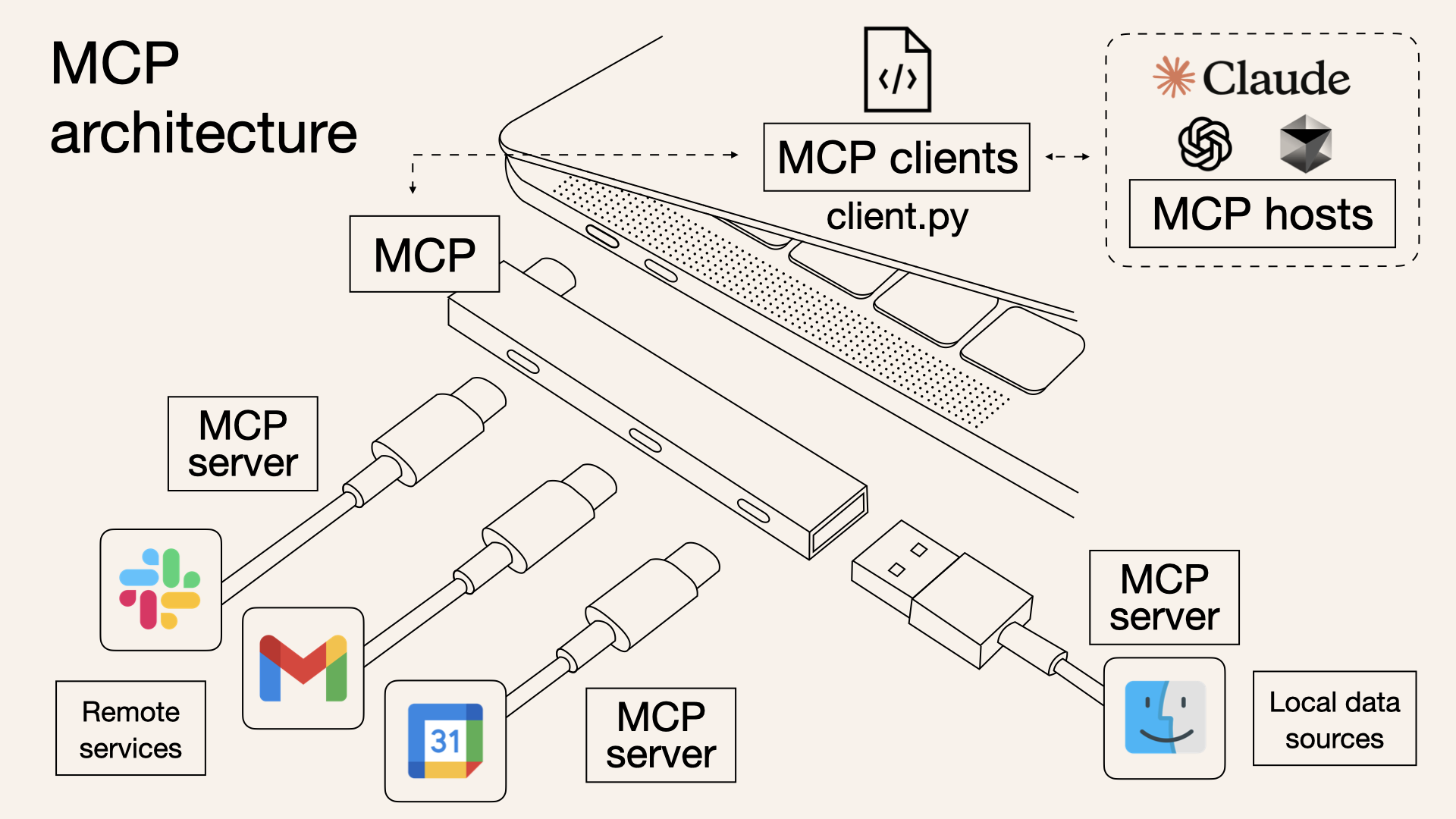
MCP Server类型分为:tools、resources、prompts等等,但目前绝大多数应用只支持到了tools,所以这边以tools为示例介绍。
如何创建一个MCP Server ?
只需要三步:
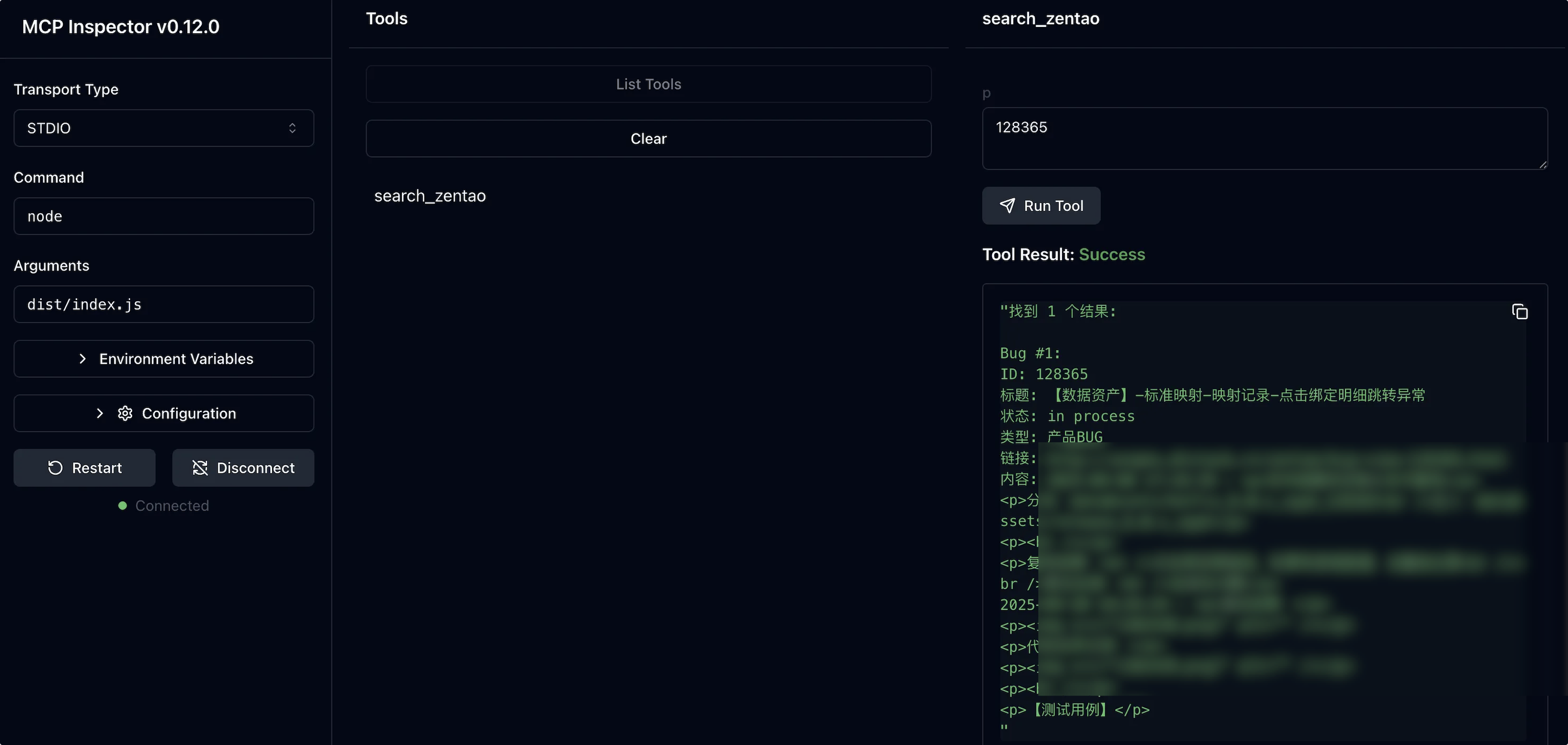
server.tool注册工具,包含工具名称,描述与工具调用时的入参格式等信息Transport 定义与客户端间的通讯方式一个非常简单的MCP Server:**ZentaoBugSearch **实现示例:
// 创建MCP服务器
const server = new McpServer({
name: "ZentaoBugSearch",
version: "1.0.0"
});
// 添加搜索禅道的工具
server.tool(
"search_zentao",
"用于搜索禅道bug",
{ p: z.string().describe("搜索关键词,可以是Bug号、标题关键词等") },
async ({ p }) => {
const searchResults = await searchZentaoBugs(p);
// 格式化结果
if (searchResults.length === 0) {
return {
content: [{ type: "text", text: "未找到匹配的Bug结果。" }]
};
}
const strictMatch = !isNaN(Number(p));
const filteredResults = strictMatch ? searchResults.filter((bug: any) => bug.id === Number(p)) : searchResults;
// 生成文本格式的搜索结果
const formattedResults = filteredResults.map((bug: any, index: number) => {
return `Bug #${index + 1}:n` +
`ID: ${bug.id}n` +
`标题: ${bug.标题}n` +
`状态: ${bug.状态}n` +
`类型: ${bug.类型}n` +
`链接: ${bug.禅道地址}n` +
`内容: ${bug.内容}n`;
}).join('n');
return {
content: [
{
type: "text",
text: `找到 ${filteredResults.length} 个结果:nn${formattedResults}`,
},
],
};
}
);
const transport = new StdioServerTransport();
await server.connect(transport);
在 Cursor 中添加MCP Servers
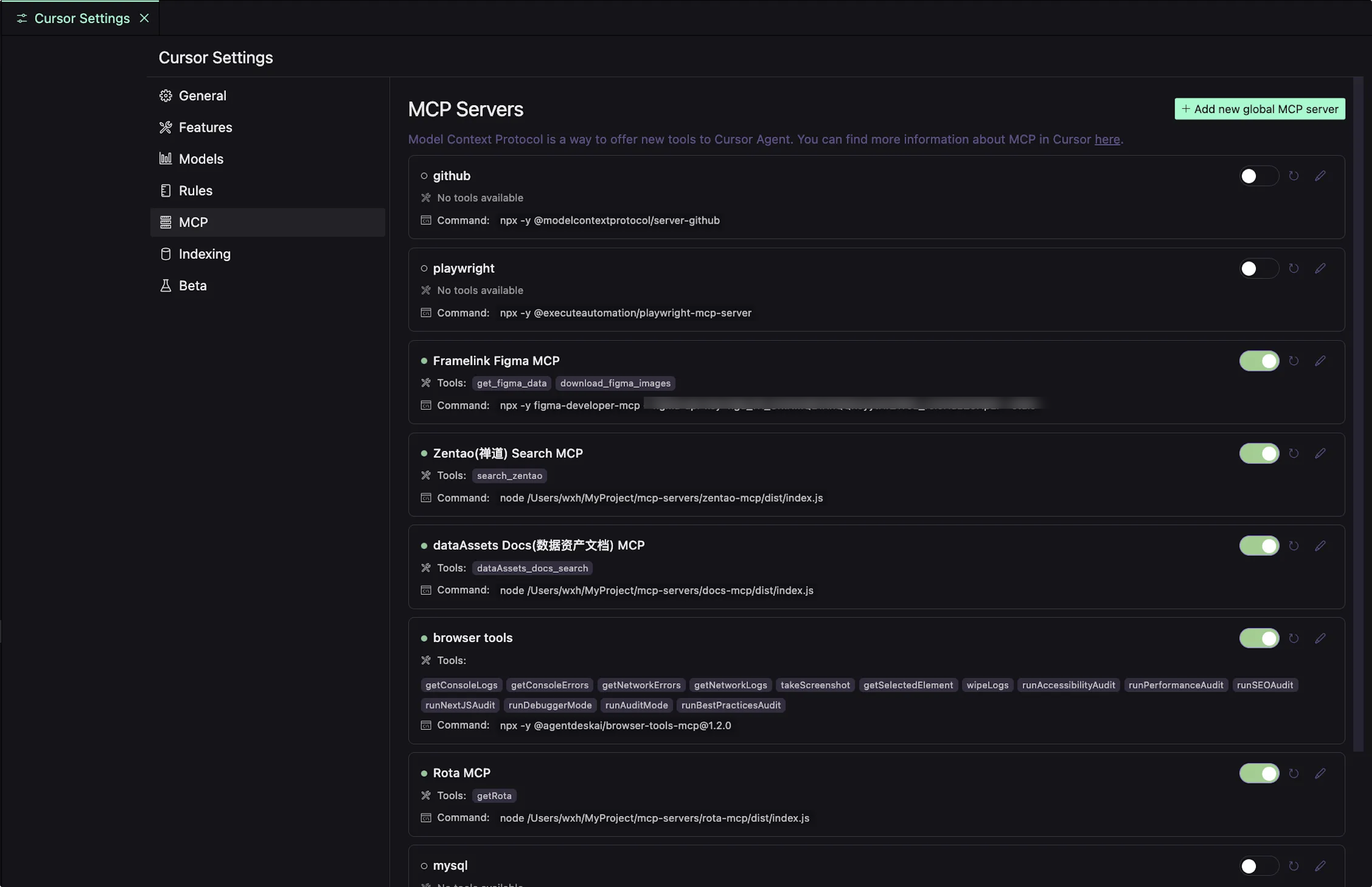
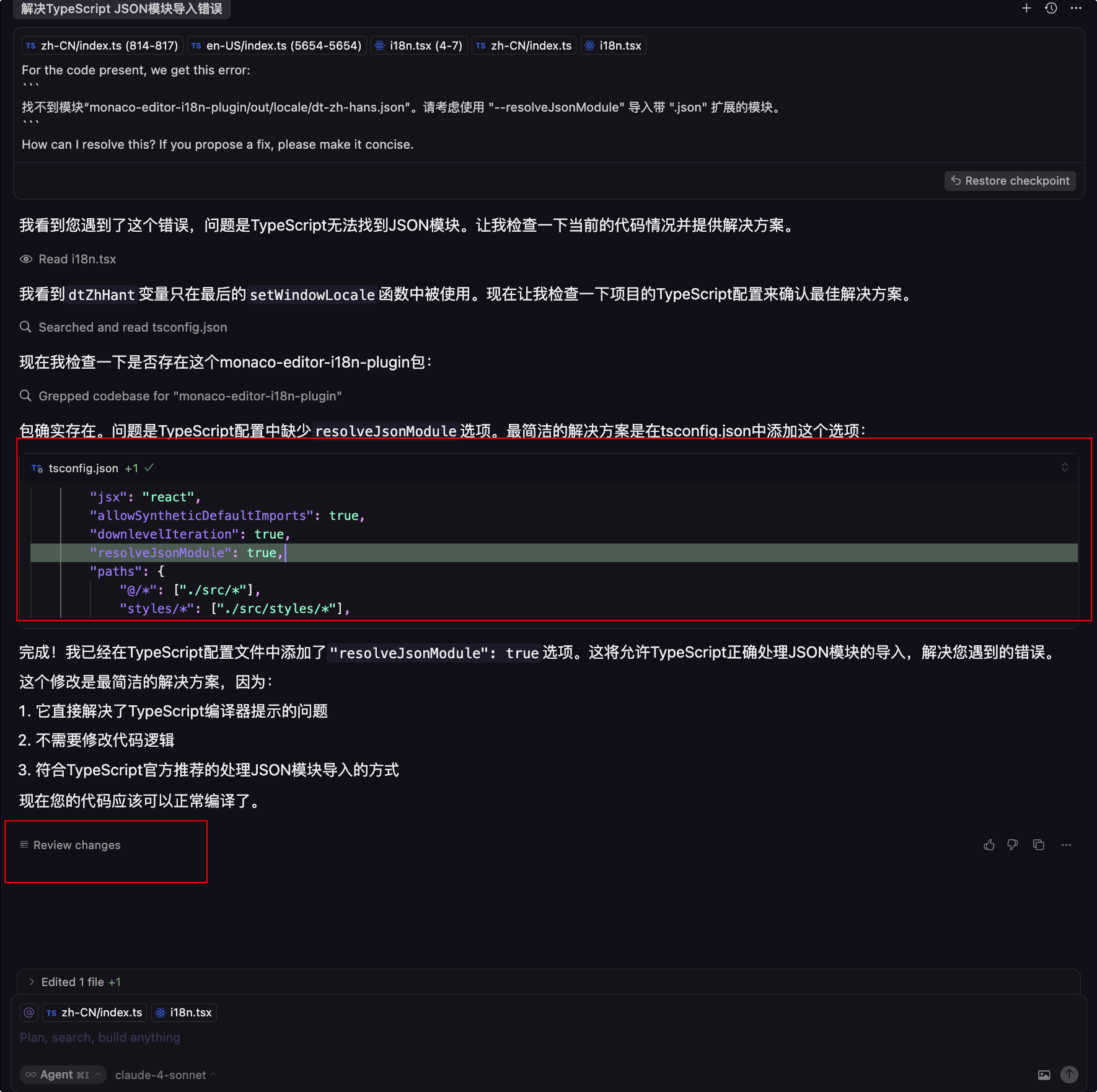
编写一个获取禅道bug信息的MCP Server,以让大模型帮我们修复bug。

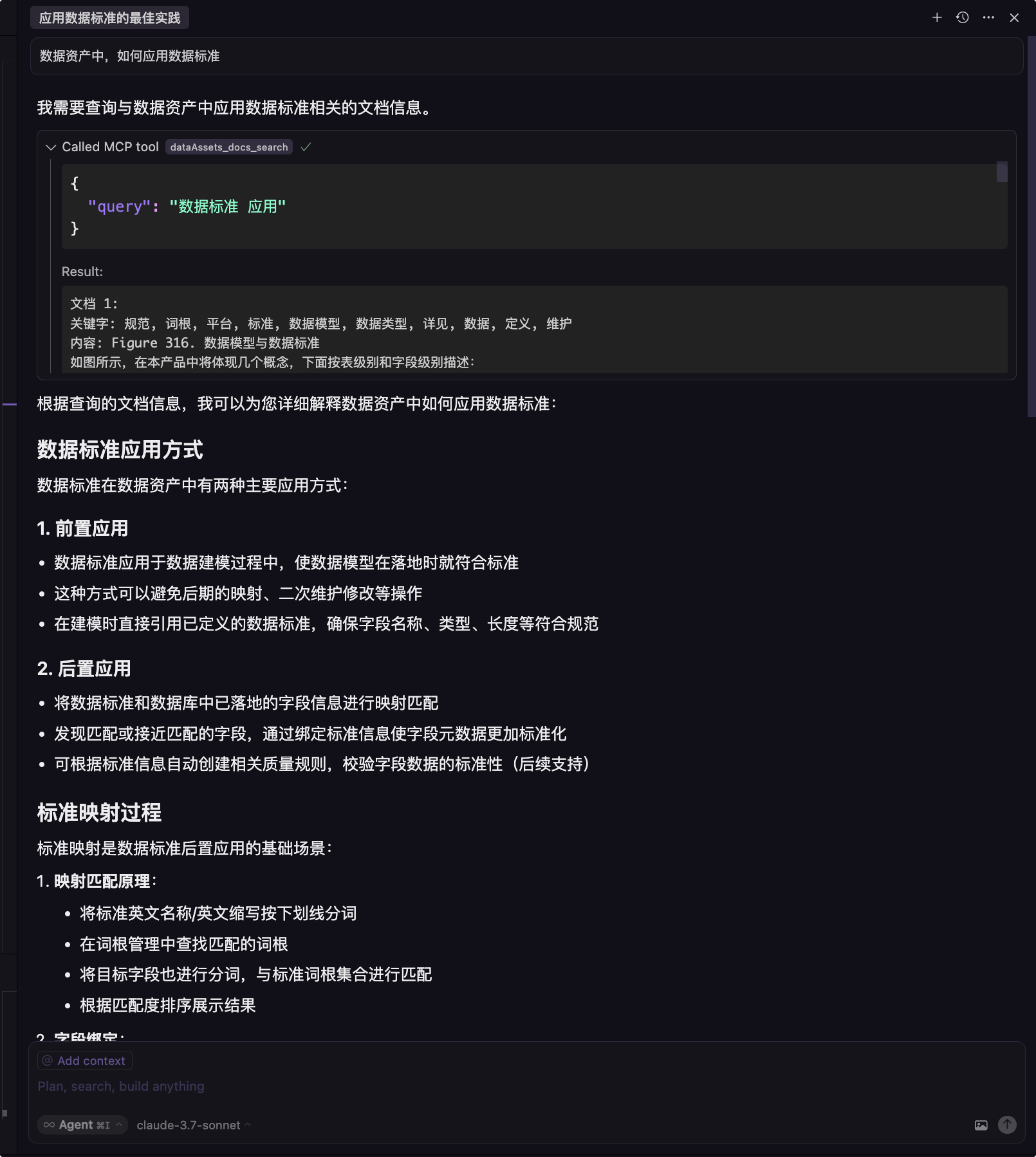
本地搭建 dify 知识库,通过 MCP 对接 dify 提供的 API,增强大模型业务理解
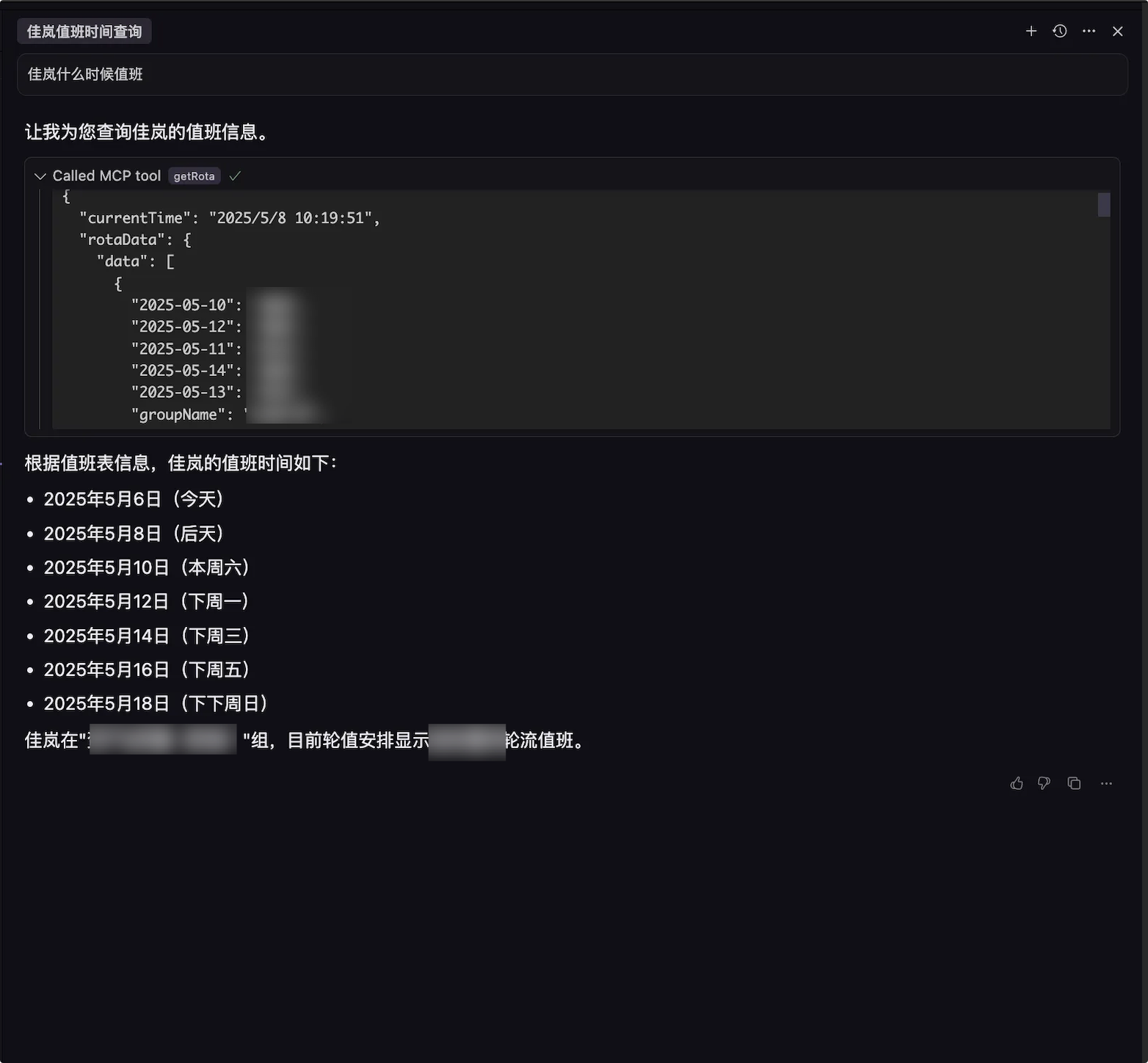
利用大模型的图像识别,直接根据 PRD 截图内容生成前端代码,完成一整个页面的基本布局与表格等UI内容,由于敏感信息过多,这里就简单描述下。
在进行产品国际化进程时,需要对产品中现有的所有中文进行提取,但基于AST提取出来的中文可能由于字符串拼接等原因,完整的语句会被拆分到多个子片段中,导致翻译困难, 而所有需要排查的文案多达3000行,因此需要借助大模型进行不符合语义化的内容排查。

1. 代码安全与隐私
2. 质量隐患
3. 开发者能力演化
AI 工具可以快速生成代码,但如果开发者在学习和工作中只依赖 AI,而不理解底层逻辑,会导致调试能力、架构设计能力和算法思维逐渐减弱。特别是初学者,在还未建立扎实基础前频繁使用自动化工具,容易形成“拿来主义”的惯性思维。
欢迎关注【袋鼠云数栈UED团队】~
袋鼠云数栈 UED 团队持续为广大开发者分享技术成果,相继参与开源了欢迎 star
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部