1. 先上代码

1 # !/usr/bin/env python 2 # ! _*_ coding:utf-8 _*_ 3 # @TIME : 2020/10/12 13:29 4 # @Author : Noob 5 # @File : bases.py 6 7 import requests 8 from bs4 import BeautifulSoup 9 import re 10 import xlwt 11 import xlrd 12 13 class Bases: 14 15 fo = open('data.txt', 'r', encoding='utf-8') 16 lines = fo.readlines() 17 18 # 说明书读取 19 def readExplain(self): 20 21 x = input("是否读取说明(y or n):") 22 if x == 'y': 23 ro = open('explain.txt', 'r+', encoding='utf-8') 24 strs = ro.read() 25 print(strs) 26 ro.close() 27 else: 28 pass 29 30 # 动态url 31 def getUrl(self, keywords, starts): 32 33 lines = self.lines 34 baseurl = lines[15].strip() 35 key = lines[17].strip() 36 fw = lines[23].strip() 37 bw = lines[25].strip() 38 39 if '.' in fw or bw: 40 fwf = fw.replace('.', '.') 41 bwf = bw.replace('.', '.') 42 else: 43 fwf = fw 44 bwf = bw 45 if fw != '': 46 url = re.sub(fwf + '(.+?)' + bwf, fw + str(starts) + bw, baseurl) 47 url = url.replace(key, keywords) 48 else: 49 url = baseurl.replace(key, keywords) 50 if '$' in url: 51 url = url[0: -1] 52 print('当前url是:%s' % url) 53 return url 54 55 # 请求头 56 def getHeader(self): 57 58 lines = self.lines 59 header = { 60 'accept': lines[5].strip(), 61 'accept-encoding': lines[7].strip(), 62 'accept-language': lines[9].strip(), 63 'cache-control': lines[11].strip(), 64 'Connection': lines[13].strip(), 65 'Upgrade-Insecure-Requests': lines[3].strip(), 66 'User-Agent': lines[1].strip() 67 } 68 return header 69 70 # 封装请求 71 def getContent(self, key='学霸', start=0): 72 73 url = self.getUrl(key, start) 74 try: 75 assert ('http' in url) 76 except: 77 return 'url有问题,请重来!!!' 78 else: 79 res = requests.get(url, headers=self.getHeader()) 80 if res.status_code == 200: 81 return res 82 else: 83 return '请求失败,状态码为:%d' % res.status_code, 'error' 84 finally: 85 # print('这是一个检查url是否正确的块') 86 pass 87 88 # 获取完整文本 89 def getContents(self, key): 90 91 lines = self.lines 92 try: 93 offset = int(lines[19]) 94 j = int(lines[21].strip()) 95 except ValueError as msg: 96 print('输入数据有错,请返回检查!!!', msg) 97 else: 98 words = lines[27].strip() 99 resText = '' 100 while 1: 101 res = self.getContent(key, j) 102 103 res.encoding = 'utf-8' # 中文乱码的时候 104 105 if type(res) == str: 106 print(res) 107 break 108 if type(res) == tuple: 109 print(res) 110 break 111 if res.status_code == 400: 112 break 113 if len(res.text) : 114 break 115 if words not in res.text: 116 break 117 if str(j) not in res.url: # 当没有页码或者滑动加载的时候,并不准确 118 resText = resText + res.text 119 break 120 resText = resText + res.text 121 j = j + offset 122 resText = resText.replace('', '') 123 resText = BeautifulSoup(resText, features='html.parser') 124 eo = open('export.txt', 'w', encoding='utf-8') 125 eo.write(str(resText)) 126 eo.close() 127 return resText 128 129 # 数据过滤 130 def getFilter(self, key): 131 132 lines = self.lines 133 resText = str(self.getContents(key)) 134 135 counts = int(lines[29].strip()) 136 137 j = 31 # 匹配规则开始下标 138 datas = [] # 所有匹配数据列表名 139 140 for i in range(counts): 141 pattern = lines[j].strip() 142 datas.append(re.compile(pattern).findall(resText)) 143 j = j + 2 144 145 # 数据爬取到TXT 146 # ao = open('abc.txt', 'a', encoding='utf-8') 147 # 148 # ao.write(ns[0] + 't' + ns[1] + 't' + ns[2] + 't' + ns[3] + 'n') # 项目名制成表头 149 # 150 # for i in range(len(datas[0])): 151 # k = '' 152 # for j in range(len(datas)): 153 # k = k + datas[j][i] + 't' 154 # ao.write(k + 'n') 155 # ao.close() 156 return datas 157 158 159 # 从Excel中读取搜索数据 160 def readExcel(self): 161 162 xd = xlrd.open_workbook('ok.xlsx') 163 sn = xd.sheet_by_index(0) 164 coms = [] 165 j = 1 166 while 1: 167 com = sn.cell_value(j, 0) 168 if com == '': 169 break 170 coms.append(com) 171 j = j + 1 172 return coms 173 174 # 数据写到Excel 175 def writeExcel(self): 176 177 data = self.readExcel() # 二维数组 178 datas = [] # 三维数组datas[a][b][c] 179 for i in range(len(data)): 180 data[i] = self.getFilter(data[i]) 181 datas.append(data[i]) 182 183 print(datas) 184 185 # 创建表 186 xt = xlwt.Workbook(encoding='gbk') 187 sn = xt.add_sheet('what') 188 189 # 制表头 190 lines = self.lines 191 # 找到匹配开始的元素索引和项目名 192 j = 0 193 for i in lines: 194 if '正则匹配规则' in i: 195 n = re.compile(r'#(.+?)#').findall(i.strip()) 196 if len(n) > 0: 197 sn.write(0, j, n[0]) # 第几行第几列值是什么 198 j = j + 1 199 200 # 单元格宽度:0的占位符是256,那么20个0就是256*20 201 if '单元格宽度' in i: 202 i = lines[lines.index(i) + 1] 203 i = i.split('*') # 字符串切割成数组 204 for k in range(len(i)): 205 sn.col(k).width = 256*int(i[k]) 206 207 # 写入数据 208 count = 1 # 计行 209 for i in datas: 210 for j in range(len(i[0])): # 每个搜索值的数量 211 for k in range(len(i)): # 搜索项数量 212 sn.write(count, k, i[k][j]) # 这里不要写错了 213 count = count + 1 214 215 return xt.save('ok.xls') # 保存格式必须是.xls,否则失败 216 217 # 运行 218 def main(self): 219 print('运行开始abc') 220 self.writeExcel() 221 222 fo.close() 223 224 if __name__ == '__main__': 225 bs = Bases() 226 bs.main()bases.py
2. 网站及其搜索项在这个txt中配置(后面有一个explain的文档有详细说明)
1 ----请输入User-Agent: 2 Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36 3 ----请输入Upgrade-Insecure-Requests: 4 1 5 ----请输入accept: 6 text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 7 ----请输入accept-encoding: 8 gzip, deflate, br 9 ----请输入accept-language: 10 zh-CN,zh;q=0.8 11 ----请输入cache-control: 12 max-age=0 13 ----请输入Connection: 14 keep-alive 15 ----请输入搜索一个数据后的完整网址: 16 http://www.biquku.la/modules/article/search.php?searchkey=%E5%AD%A6%E9%9C%B8 17 ----请输入网址中的关键词: 18 %E5%AD%A6%E9%9C%B8 19 ----请输入页码差或滑动偏移量(没有就填0): 20 0 21 ----请输入默认开始页数或者第一条数据(没有就填0): 22 0 23 ----请输入偏移量前面的字符(没有页码就不填): 24 25 ----请输入偏移量后面的字符(没有页码不填,如果有页码,但是页码后面没有字符输入$): 26 27 ----请输入需要中断请求的连续字符(可以为空,也有可能导致死循环,比如前程无忧,会无限发送请求,根据网站来): 28 29 ----请输入匹配项目数量 30 4 31 ----请输入第一条要输出内容#文章名称#的正则匹配规则 32 /" target="_blank">(.+?) 33 ----请输入第二条要输出内容#最新章节#的正则匹配规则 34 .html" target="_blank">(.+?) 35 ----请输入第三条要输出内容#作者#的正则匹配规则 36data.txtclass="nowrap">(.+?) 37 ----请输入第四条要输出内容#更新日期#的正则匹配规则 38(.+?) 39 ----请输入第五条要输出内容##的正则匹配规则 40 41 ----请输入单元格宽度(大概字符个数): 42 30*30*20*20
3. 关键字数据写在Excel中:ok.xlsx
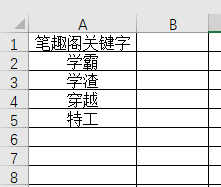
4. 输出的有三个文本
--export.txt:输出整个文档,方便写正则规则
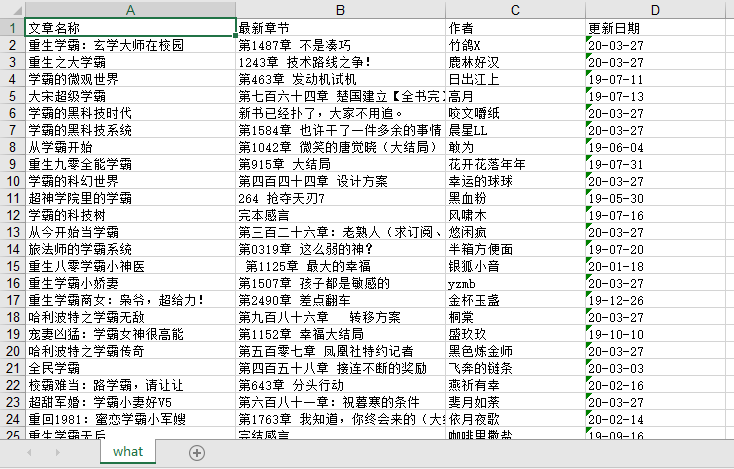
--ok.xls:输出爬取的数据
--abc.txt:输出爬取数据,代码被注释了,看自己需要
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部
