很多刚入行甚至想入行数据分析的朋友,往往会陷入一个误区:以为数据分析就是不停地做报表、画饼图。
其实,数据分析的核心魅力在于 “推断”——即见微知著。
在现实生活中,我们很难获取“全量数据”(比如你不可能调查全国每一个人的身高),那么,如何通过手中的“小样本”去推测“大总体”的规律?
这就需要用到统计学中的推断分析。
本文将结合代码来介绍推断分析中最常用的三大方法:参数估计、假设检验、非参数检验。
想象你在煮一锅排骨汤。你想知道汤咸不咸,你不会把整锅汤都喝完,而是舀起一勺尝一尝。
参数估计就是:根据样本的特征(比如样本均值),去估计总体的特征(比如总体均值)。
它通常分为两种:
区间估计是最常使用的方式,下面通过一个示例来演示参数估计的具体使用。
import numpy as np
from scipy import stats
# 1. 模拟数据
np.random.seed(42)
true_mean = 15 # 上帝视角的真实均值
sample_salaries = np.random.normal(loc=true_mean, scale=3, size=100) # 模拟100个样本
# 2. 计算统计量
sample_mean = np.mean(sample_salaries)
sample_std = np.std(sample_salaries, ddof=1)
n = len(sample_salaries)
# 计算95%置信区间
# 这里的 scale 使用的是标准误 (Standard Error) = 样本标准差 / sqrt(n)
conf_int = stats.t.interval(
confidence=0.95, df=n - 1, loc=sample_mean, scale=sample_std / np.sqrt(n)
)
lower_bound, upper_bound = conf_int
print(f"样本均值: {sample_mean:.2f}k")
print(f"95%置信区间: [{lower_bound:.2f}k, {upper_bound:.2f}k]")
# 运行结果:
'''
样本均值: 14.69k
95%置信区间: [14.15k, 15.23k]
'''
图形化之后的结果如下:
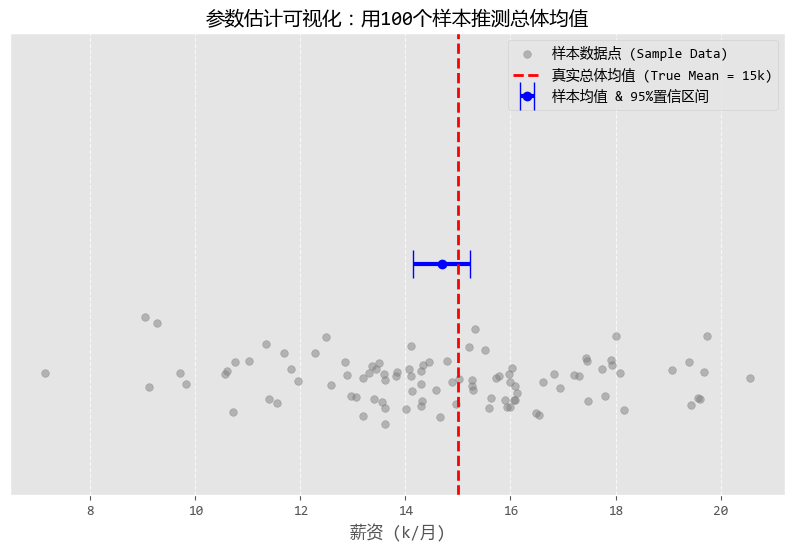
从图中可以看出:
数据分析不是算命,算出来的不是一个死的数字,而是一个科学的范围。
我们就是用参数估计的方法,在不确定性中寻找确定性。
假设检验是数据分析中最常用的决策工具。它的逻辑是:先立一个Flag(假设),然后看证据(数据)是否打脸。
下面通过一个电商APP的A/B测试场景,来演示假设检验的使用。
假设某电商APP想把 “购买” 按钮从 蓝色 改成 红色 。
我们采集了两组用户的消费金额数据来进行T检验。
# 1. 模拟AB测试数据
# 蓝色按钮组(对照组):平均消费 100元
group_blue = np.random.normal(loc=100, scale=20, size=1000)
# 红色按钮组(实验组):平均消费 105元 (我们要检验这个提升是否显著)
group_red = np.random.normal(loc=105, scale=25, size=1000)
# 2. 进行独立样本T检验 (T-test)
t_stat, p_val = stats.ttest_ind(group_blue, group_red)
print(f"P值: {p_val:.5f}")
# 3. 判断结论
alpha = 0.05
if p_val 图形化结果如下:
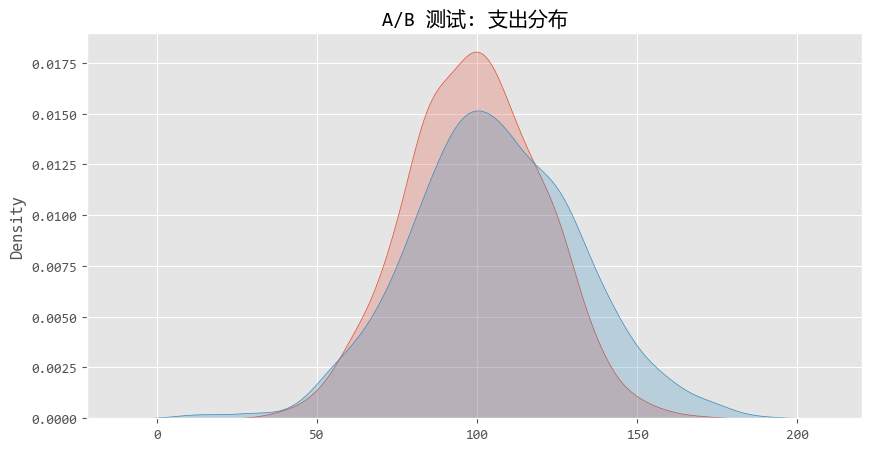
从图中,我们可以看出,两条曲线(红色和蓝色)其实重叠度很高。
对于新手,看到这个图,可能会陷入一个误区,觉得“这两座山峰看起来差不多嘛,没啥区别”。
但在统计学上,两座山峰的 “重心” (均值)发生了 显著偏移 。这就是假设检验的威力--在重叠的噪声中识别出偏移的信号。
前面的 “参数估计” 和 “T检验” 都有一个娇气的脾气:它们通常假设数据是服从 “正态分布” 的(也就是漂亮的钟形曲线)。
但在现实生活中,很多数据并不正态,或者数据甚至是定序的(比如:非常满意、满意、一般、不满意)。
这时候,传统的 T检验 就失效了,我们需要请出 非参数检验 。
它不依赖数据的分布形状,非常抗造。
假设我们要对比两款手游《王者荣耀》和《原神》玩家每天的游玩时长。
由于《原神》玩家可能存在大量的“长尾”用户(玩特别久),数据往往是严重右偏的,不符合正态分布。
这时候对比两组数据差异,就不能用T检验,我们使用非参数估计中的一种方式:曼-惠特尼U检验 (Mann-Whitney U test)。
# 1. 模拟非正态分布数据 (使用指数分布模拟由偏数据)
# 游戏A:平均时长较短
game_a_hours = np.random.exponential(scale=1.0, size=100)
# 游戏B:平均时长较长
game_b_hours = np.random.exponential(scale=1.5, size=100)
# 2. 首先,检查一下正态性 (Shapiro-Wilk检验)
# 如果P 可视化结果如下:
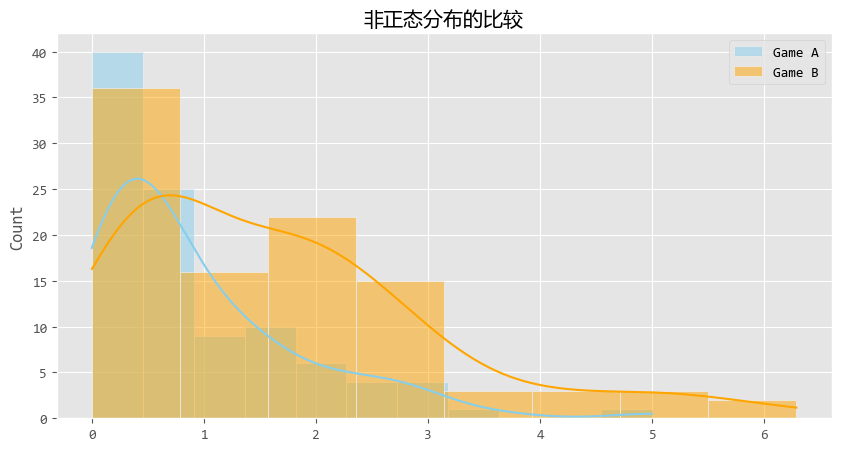
尽管数据长得歪瓜裂枣(严重右偏),U检验依然稳健地告诉我们:这两组数据不一样。
U检验比较的不仅仅是平均值,它更多是在比较 “秩次”(Ranking)。
通俗点说,它发现如果我们把两组玩家混在一起排名,Game B的玩家即使不看具体时长,排名也普遍比Game A的玩家靠前。
从图中来看,你会看到橙色(Game B)的尾巴明显比蓝色(Game A)拖得更长、更厚实。
这说明Game B(比如《原神》)更容易让玩家沉浸更久,或者拥有更多的重度玩家。
恭喜你!你已经掌握了数据推断分析的核心逻辑:
这三板斧是数据分析师行走江湖的必备技能。掌握了它们,你就不仅仅是一个“做表的”,而是一个能从数据中挖掘真相的“侦探”!
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部