这次的目标网址是:https://www.bizhi888.com/e/sch/index.php?page=0&keyboard=美女&field=2&sear=1
思路:由于这次搜索的目标网页是分页式的,所以采用requests+lxml技术爬取数据。但是这次的网站图片数据累计4296张图片,如果采用单线程爬取这些数据,那么爬完所有数据将多花费一些时间,而如果采用多线程ThreadPoolExecutor技术,那么爬取数据的速度将会大大提高。
下面是目标网页
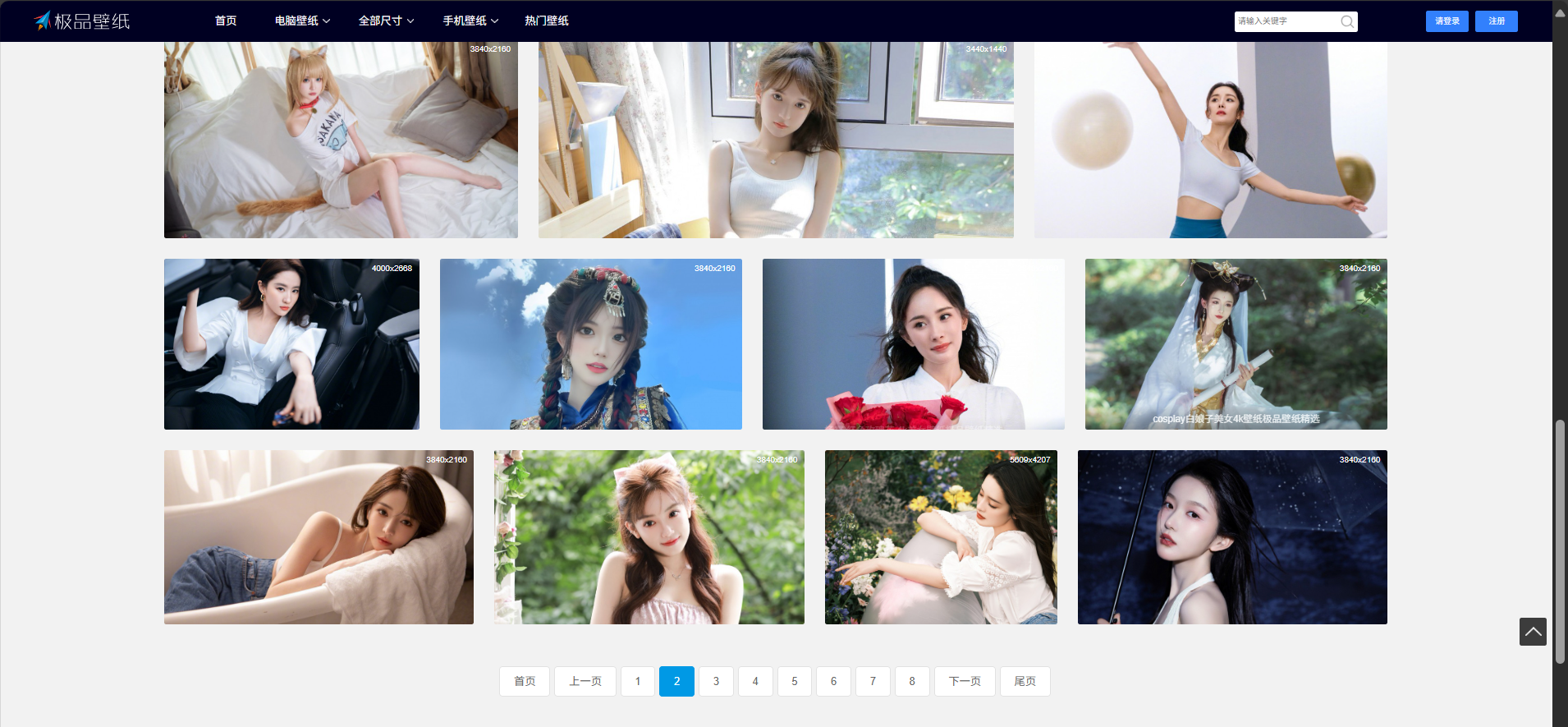
由于所有页面的的url链接只有一个参数不同,所有采用循环的方式,将其封装成一个列表url_list并返回。
def create_urls():
url_list =[]
url = 'https://www.bizhi888.com/e/sch/index.php?page=0&keyboard=%E7%BE%8E%E5%A5%B3&field=2&sear=1'
#共计120页图片
for page in range(10,120):
url = f'https://www.bizhi888.com/e/sch/index.php?page={page}&keyboard=%E7%BE%8E%E5%A5%B3&field=2&sear=1'
url_list.append(url)
return url_list
img_url_dict是一个字典,键是图片的名字,值是图片的url,这样封装好后,方便后面的调用。
def download_img(img_url_dict):
if os.path.exists(f'./img')==False:
os.makedirs(f'./img')
for key in img_url_dict:
resp = requests.get(img_url_dict[key],headers=header)
with open(f'./img/{key}','wb') as f:
f.write(resp.content)
f.close()
下面是爬虫模块,其中将图片的src链接中的newpc202302替换成lan20221010,可以提高图片的清晰度,尽管最终获得的图片依然不是4K高清的,但已经较为清晰。
#爬虫模块
def spider(url):
#数据字典
img_url_dict = {}
#爬取网页源代码
resp = requests.get(url,headers=header)
resp.encoding='utf8'
#使用etree解析源码
html = etree.HTML(resp.text)
#找到所有图片的标签
a_list = html.xpath('/html/body/div[4]/a')
for a in a_list:
#获取图片的src
img_src = a.xpath('img/@data-original')[0]
#将src链接中的newpc202302替换成lan20221010,则提高图片的清晰度
img_url = img_src.replace('newpc202302','lan20221010')
#取链接最后15位为图片的名字
img_name = img_url[-15:]
#将name和url添加进集合
img_url_dict[img_name] = img_url
#下载图片
download_img(img_url_dict)
#爬完一页后打印到控制台
global page
print(f'第{page}页数据爬取完成!')
page+=1
使用ThreadPoolExecutor函数,开五个线程同时爬取网页图片
if __name__ == '__main__':
#创建url列表
url_list = create_urls()
#使用多线程爬取网页数据
with ThreadPoolExecutor(5) as t:
for url in url_list:
t.submit(spider(url))
import requests
from lxml import etree
import os
from concurrent.futures import ThreadPoolExecutor
header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0'
}
page=1
# 将需要的网页网址加入到url_list列表,方便后面多线程爬取
def create_urls():
url_list =[]
url = 'https://www.bizhi888.com/e/sch/index.php?page=0&keyboard=%E7%BE%8E%E5%A5%B3&field=2&sear=1'
#共计120页图片
for page in range(10,120):
url = f'https://www.bizhi888.com/e/sch/index.php?page={page}&keyboard=%E7%BE%8E%E5%A5%B3&field=2&sear=1'
url_list.append(url)
return url_list
#爬虫模块
def spider(url):
#数据字典
img_url_dict = {}
#爬取网页源代码
resp = requests.get(url,headers=header)
resp.encoding='utf8'
#使用etree解析源码
html = etree.HTML(resp.text)
#找到所有图片的标签
a_list = html.xpath('/html/body/div[4]/a')
for a in a_list:
#获取图片的src
img_src = a.xpath('img/@data-original')[0]
#将src链接中的newpc202302替换成lan20221010,则提高图片的清晰度
img_url = img_src.replace('newpc202302','lan20221010')
#取链接最后15位为图片的名字
img_name = img_url[-15:]
#将name和url添加进集合
img_url_dict[img_name] = img_url
#下载图片
download_img(img_url_dict)
#爬完一页后打印到控制台
global page
print(f'第{page}页数据爬取完成!')
page+=1
def download_img(img_url_dict):
if os.path.exists('./img')==False:
os.makedirs('./img')
for key in img_url_dict:
resp = requests.get(img_url_dict[key],headers=header)
with open('./img/{key}','wb') as f:
f.write(resp.content)
f.close()
if __name__ == '__main__':
#创建url列表
url_list = create_urls()
#使用多线程爬取网页数据
with ThreadPoolExecutor(5) as t:
for url in url_list:
t.submit(spider(url))
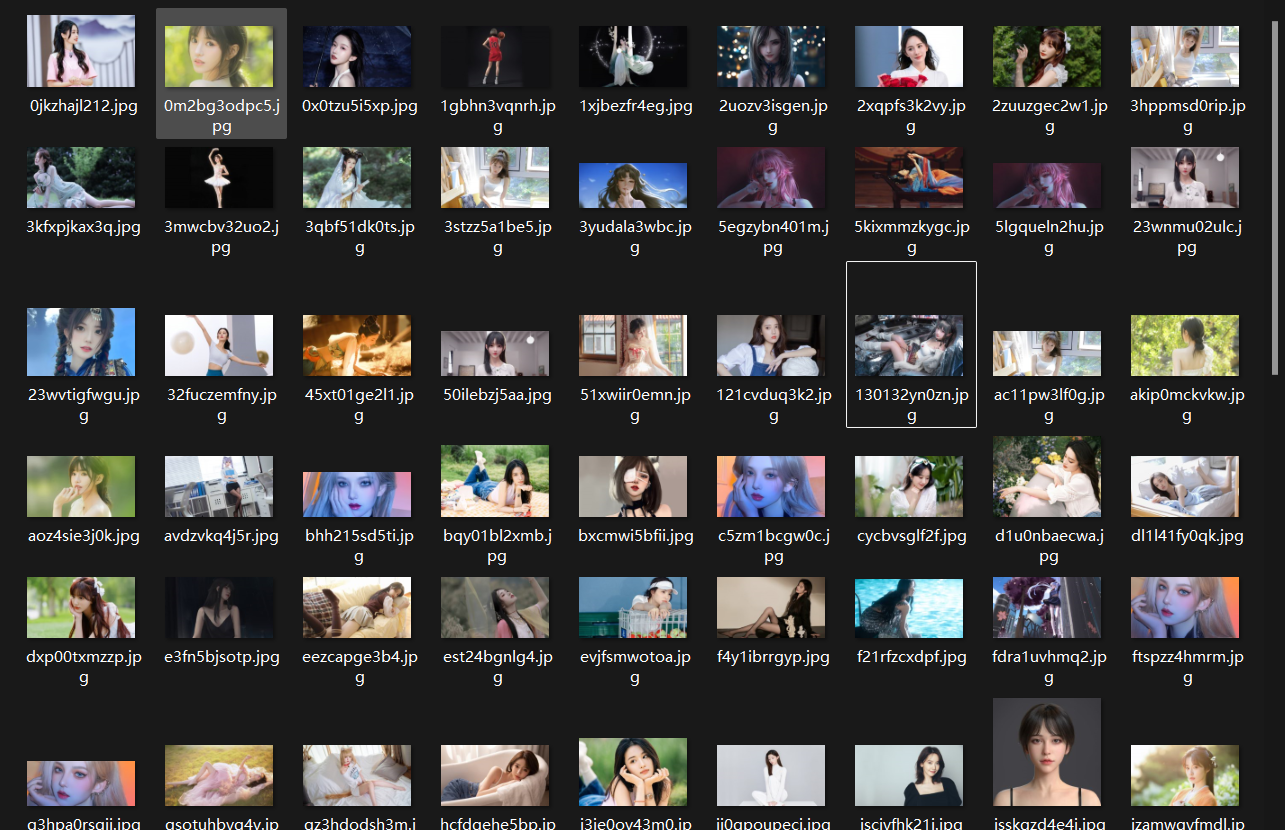
下面让我们看结果
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部