目标网址:4K壁纸高清图片_电脑桌面手机全面屏壁纸4K超清_高清壁纸4K全屏 - 壁纸汇
使用技术Selenium+Requests
下面是目标网页
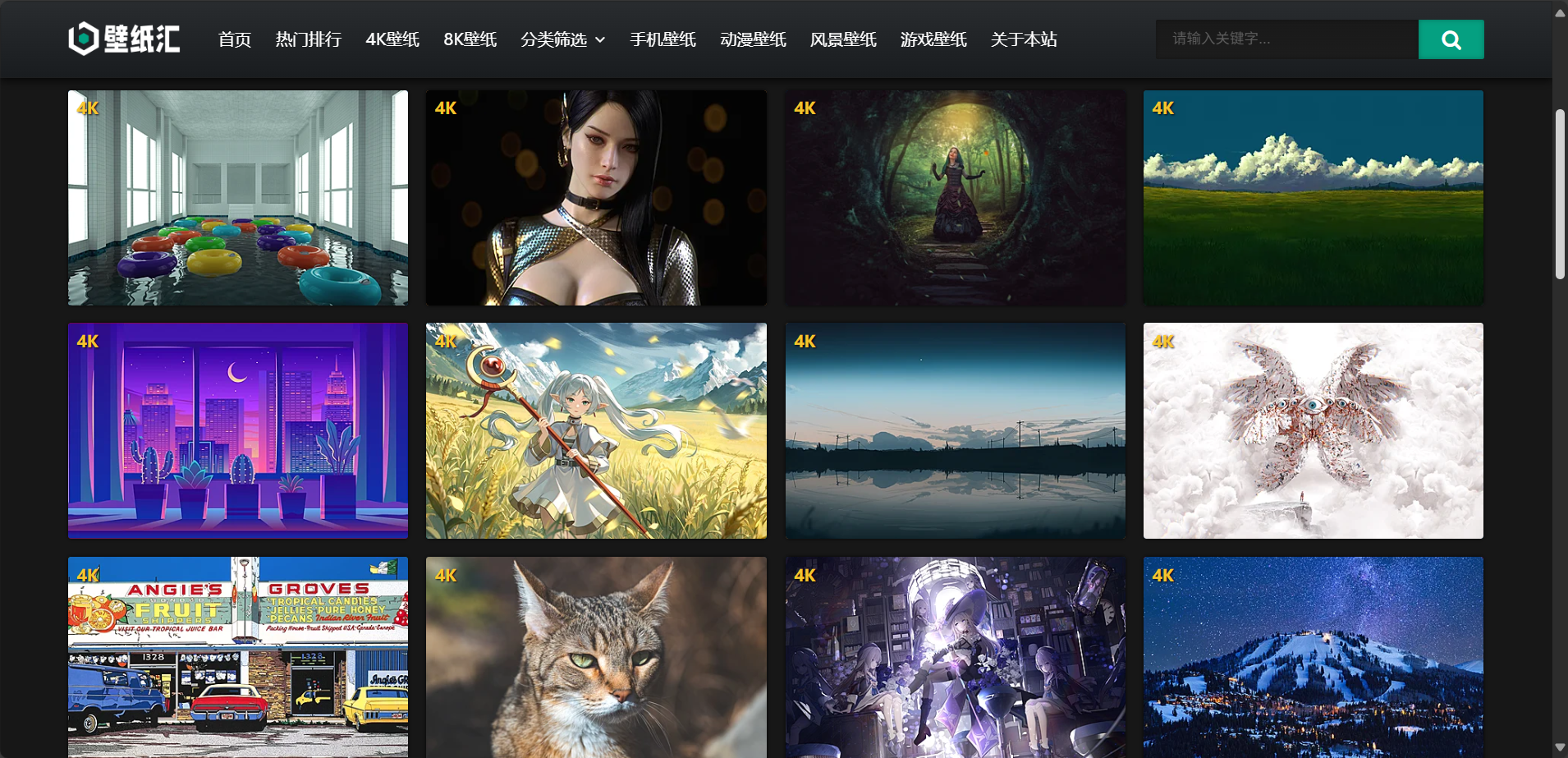
思路:由于此网页是通过不断下拉的方式刷新图片,而不是通过分页的方式加载新的图片,所以不能使用requests+xpath技术直接爬取该网页,所以采用Selenium操作网页,控制网页下滑获取最新图片。下面让我们来看代码。
第一步:首先设置无头显示,再打开目标网页。
from selenium.webdriver import Edge from selenium.webdriver.common.by import By import time from selenium.webdriver.edge.options import Options import requests import os import shutil #设置无头显示 opt = Options() opt.add_argument("--headless") opt.add_argument("--disable-gpu") web = Edge(options=opt) #打开目标网页 url = 'https://www.bizhihui.com/tags/4Kbizhi/' web.get(url) time.sleep(1) #每次操作网页时必须让程序睡眠1秒,否则容易导致网页刷新失败,程序中断报错
第二步:通过不断循环不断下拉滚动条获取最新图片数据。
#滚动条设置 for i in range(5): web.execute_script('document.documentElement.scrollTop=10000') #设置滚动条滚到最底下,0是顶部,10000是底部 time.sleep(2)
第三步:通过find_elements(By.TAG_NAME,'li')函数,获取该页面所有的li标签,并且筛选目标li标签,通过get_attribute('src')函数获取img标签的src属性,最后获取到图片的url和name,将它们放进字典img_url_list中。
#获取所有li标签 lis = web.find_elements(By.TAG_NAME,'li') time.sleep(1) #通过li标签爬取目标图片的url img_url_list = {} for li in lis: if li.get_attribute('class')=='item-list masonry-brick':#筛选class=item-list masonry-brick的li标签 img_src = li.find_element(By.TAG_NAME,'img').get_attribute('src') #获取img标签的src属性 img_url = img_src[:-9] img_name = img_url[-17:] img_url_list[img_name]=img_url
第四步:通过os模块自带的函数判断文件夹是否存在,如果存在则通过shutil模块的rmtree方法删除,再通过os模块下的makedirs方法创建目录。
#判断文件夹是否存在,如果存在则删除,在创建 if os.path.exists('./img'): shutil.rmtree('./img') #删除文件夹 os.makedirs('./img') #创建文件夹
第五步:循环上面得到的字典,通过requests方法下载图片并保存在新建的img文件夹中
#循环字典下载图片 i=1 for key in img_url_list: resp = requests.get(img_url_list[key]) with open(f'./img/{key}','wb') as f: f.write(resp.content) print(f"下载{i}张图片。。。") i+=1 f.close() #关闭文件 #下载完成 print("OVER!") #结束进程 web.close()
通过以上步骤我们就爬取到了网页上的图片了。
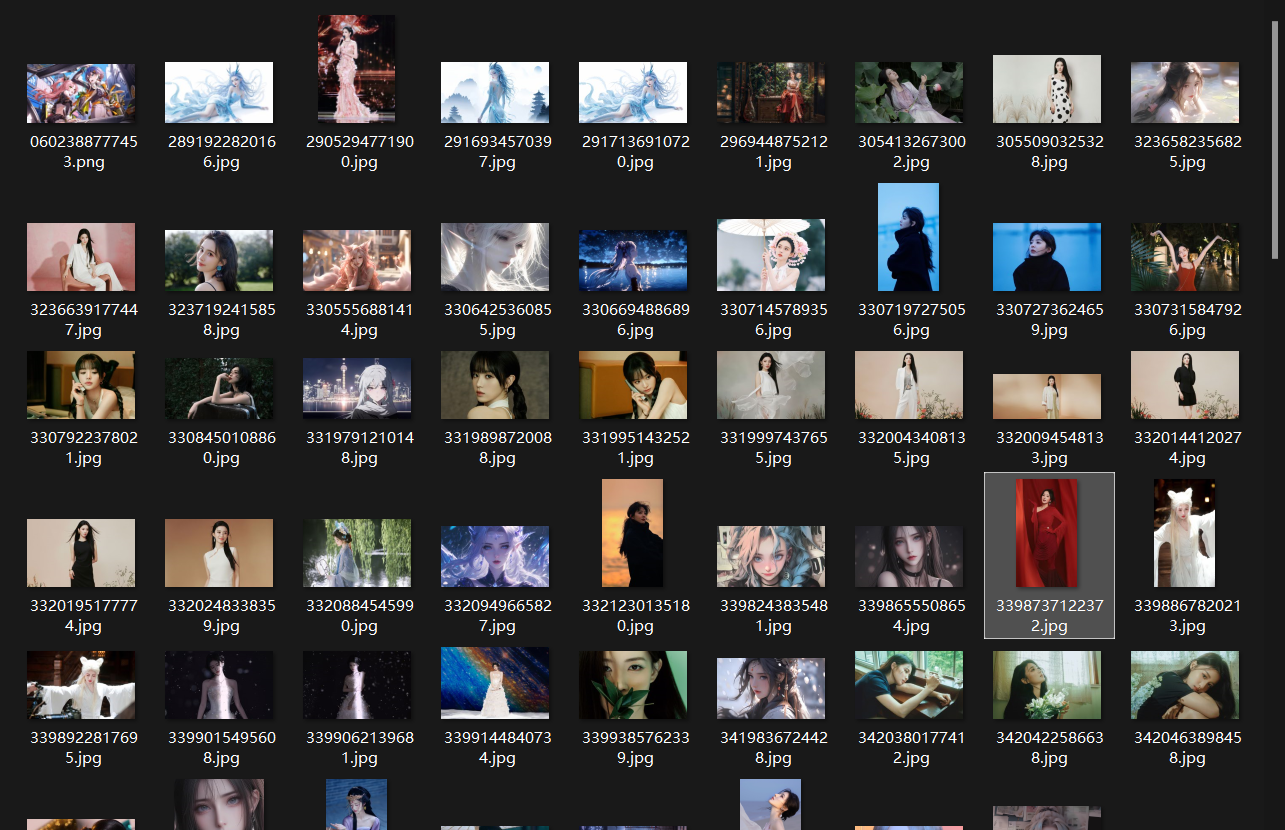
下面时程序源码:
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.edge.options import Options
import requests
import os
import shutil
#设置无头显示
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
web = Edge(options=opt)
# web = Edge()
#打开目标网页
url = 'https://www.bizhihui.com/tags/4Kbizhi/'
web.get(url)
time.sleep(1)
#滚动条设置
for i in range(5):
web.execute_script('document.documentElement.scrollTop=10000') #设置滚动条滚到最底下,0是顶部,10000是底部
time.sleep(2)
#获取所有li标签
lis = web.find_elements(By.TAG_NAME,'li')
time.sleep(1)
#通过li标签爬取目标图片的url
img_url_list = {}
for li in lis:
if li.get_attribute('class')=='item-list masonry-brick': #筛选class=item-list masonry-brick的li标签
img_src = li.find_element(By.TAG_NAME,'img').get_attribute('src') #获取img标签的src属性
img_url = img_src[:-9]
img_name = img_url[-17:]
img_url_list[img_name]=img_url
#判断文件夹是否存在,如果存在则删除,在创建
if os.path.exists('./img'):
shutil.rmtree('./img') #删除文件夹
os.makedirs('./img') #创建文件夹
#循环字典下载图片
i=1
for key in img_url_list:
resp = requests.get(img_url_list[key])
with open(f'./img/{key}','wb') as f:
f.write(resp.content)
print(f"下载{i}张图片。。。")
i+=1
f.close() #关闭文件
#下载完成
print("OVER!")
#结束进程
web.close()
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部