
本文首发于 NebulaGraph 布道师古思为的个人博客,是一个基于 NebulaGraph 图算法、图数据库、机器学习、GNN 的 Fraud Detection 方法综述。
除了基本方法思想的介绍之外,我还给大家弄了可以跑的 Playground。值得一提的是,这是第一次给大家介绍 Nebula-DGL 这个项目。
基于图数据库的欺诈检测方法
1.1 建立图谱
首先,对现有的历史数据、标注信息面向关联关系进行属性图建模。这种原始数据是多个表结构中的银行、电子商务或者保险行业里的交易事件记录、用户数据和风控标注,而建模过程就是抽象出我们关心的实体、实体间的关联关系、和其中有意义的属性。
一般来说,自然人、公司实体、电话号码、地址、设备(比如终端设备、网络地址、终端设备所连接的 WiFi SSID 等)、订单都是实体本身,其他信息比如风险标注(是否高风险、风险描述等)、自然人和公司实体的信息(职业、收入、学历等)都作为实体的属性来建模。
下图是一个可以参考的贷款反欺诈的示例建模,它来自一份作者开源的图结构数据生成项目。
注,你可以访问 https://github.com/wey-gu/fraud-detection-datagen 获取这个开源的数据生成器代码和一份示例的数据。

1.2 图数据库查询识别风险
有了一张囊括了人、公司、历史贷款申请记录、电话、线上申请网络设备的图谱,我们可以挖掘一些有意思的信息。
事实上,很多被发现、并有效被阻止从而止损的骗保行为是具有群体聚集性的。比如欺诈团伙可能是一小批人(比如 3 到 5 人)有组织地收集更大规模的身份证信息(比如 30 张),同时发起多个金融机构大量贷款,然后在放款后选择丢弃这批留下了违约记录的身份证,再进一步选择下一批身份证信息如法炮制。
这种团伙作案的方式因为利用了大量新的身份信息,完全利用历史记录去黑名单规避风险的方式是无效的。不过,借助于关联关系的视角,这些模式是一定程度上可以被及时识别出来的。
这些可以被识别出的规律我把它分成两种:
一种是风控专家可以直接用某种模式来描述的,例如:和已经被标注为高风险的实体有直接或者间接的关联关系(新订单申请人使用了和过往高风险记录相同的网络设备),这种模式对应到图谱中,通过一个图查询就可以实时给出结果。
另一种是隐含在数据的关联关系背后,需要通过图算法挖掘得出的一些风险提示,例如:尽管给定的实体与有限的标注高风险实体没有匹配的关联,但是它在图中形成了聚集性可能提示我们这可能是一个尚未得手的进行中的团伙贷款诈骗的其中一次申请,这种情况可以通过定期在历史数据中批量执行社区发现算法得出,并在高聚集社区中利用中心性算法给出核心实体,一并提示给风险专家进行后续评估和风险标注。
1.2.1 基于图谱与专家图模式匹配的欺诈检测示例
在开始之前,我们利用 Nebula-UP 来一键部署一套 NebulaGraph 图数据库:
更多请参考 https://github.com/wey-gu/nebula-up/
curl -fsSL nebula-up.siwei.io/install.sh | bash首先,我们把前边建模的图谱加载到 NebulaGraph 里:
# 克隆数据集代码仓库
git clone https://github.com/wey-gu/fraud-detection-datagen.git
cp -r data_sample_numerical_vertex_id data
# 去掉表头
sed -i '1d' data/*.csv
docker run --rm -ti
--network=nebula-net
-v ${PWD}:/root/
-v ${PWD}/data/:/data
vesoft/nebula-importer:v3.1.0
--config /root/nebula_graph_importer.yaml有了这样一个图谱,风控专家可以在可视化探索工具中按需探索实体之间的关系,绘制相应的风险模式:
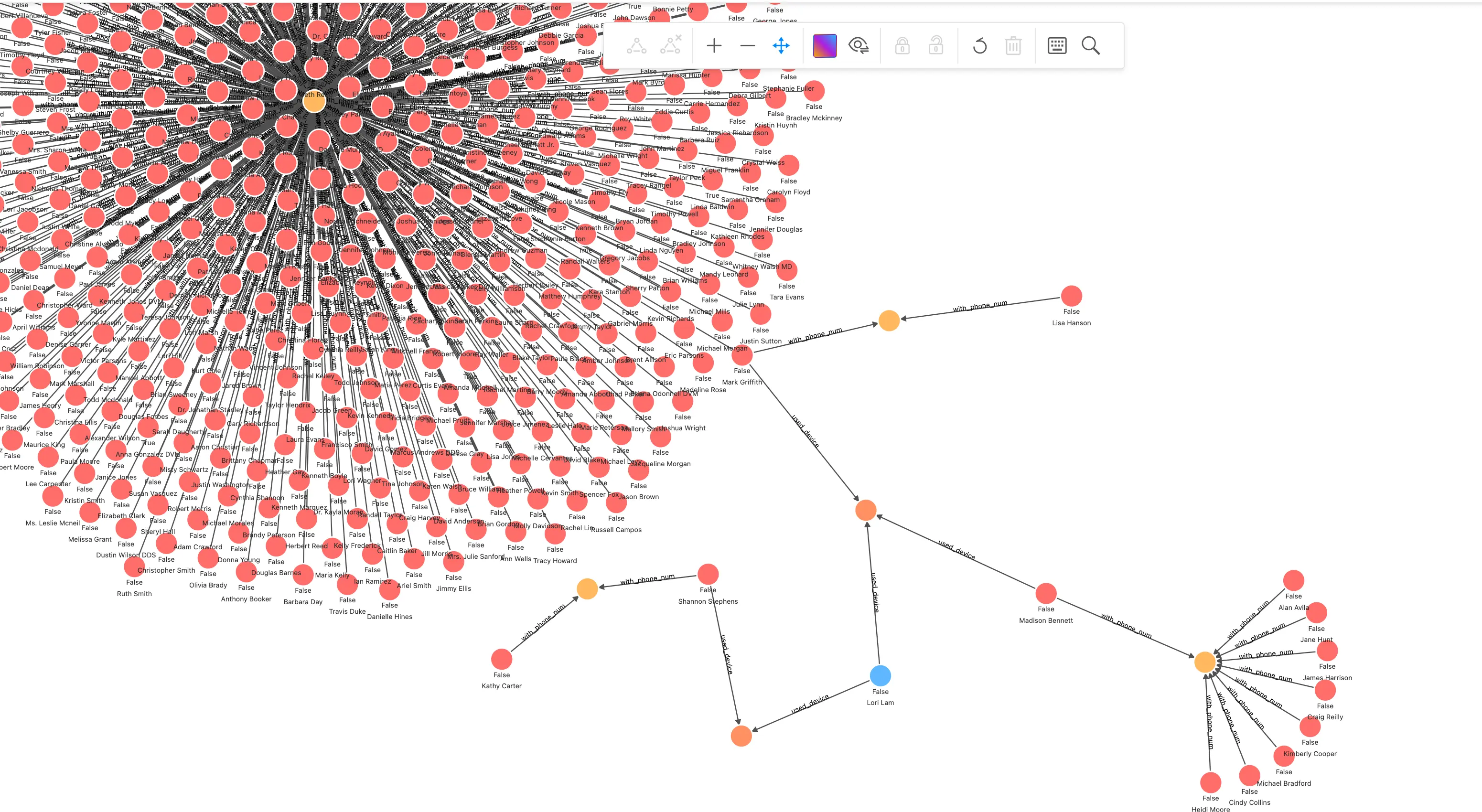
在这个探索截图里,我们可以明显看到一个群控设备的风险模式,这个模式可以被交给图数据库开发者,抽象成可以被风控应用定期、实时查询的语句:
## 针对一笔交易申请关联查询
MATCH (n) WHERE id(n) == "200000010265"
OPTIONAL MATCH p_shared_d=(n)-[:used_device]->(d)(pn:phone_num)我们可以很容易在此模型之上,通过修改返回的关联设备计数,作为意向指标查询的判断 API:
## 群控指标
MATCH (n) WHERE id(n) == "200000010265"
OPTIONAL MATCH p_shared_d=(n)-[:used_device]->(d)(pn:phone_num)如此,我们可以建立一个相对有效的风控系统,利用有限的标注数据和专家资源,去更高效控制团伙欺诈作案风险,然而,在现实情况下,我们的大多数标注数据的获取还是过于昂贵,那么有没有什么方法是更有效利用有限的风险标注和图结构,来预测出风险呢?
1.3 利用图扩充标注
答案是肯定的, Xiaojin Z. 和 Zoubin G. 在论文:Learning from Labeled and Unlabeled Data with Label Propagation http://mlg.eng.cam.ac.uk/zoubin/papers/CMU-CALD-02-107.pdf(CMU-CALD-02-107)中,利用标签传播(Label Propagation)算法来把有限的标注信息在图上通过关联关系传播到更多实体中。
这样,在我们建立的图谱中,我们可以很容易地借助有限的高风险标注,去“传播”产生更多的标注信息。这些扩展出来的标注信息一方面可以在实时的图查询中给出更多的结果,另一方面,它还能作为风控专家重要的输入信息,帮助推进反欺诈调查行动的开展。
一般来说,我们可以通过定期离线地全图扫描数据,通过图算法扩充、更新标注,再将有效的更新标注写回到图谱之中。
1.3.1 图算法扩充欺诈风险标注的示例
下面,我给出一个可以跑通的案例:
这个例子中,我用到了 Yelp 这个欺诈识别的经典数据,这份数据不只会用在这个例子中,后边 GNN 方法中的案例我也会用到它,所以大家可以耐心把数据导入 NebulaGraph。
生成导入的方法在这里,https://github.com/wey-gu/nebulagraph-yelp-frauddetection
cd ~
git clone https://github.com/wey-gu/nebulagraph-yelp-frauddetection
cd nebulagraph-yelp-frauddetection
python3 -m pip install -r requirements.txt
python3 data_download.py
# 导入图库
docker run --rm -ti
--network=nebula-net
-v ${PWD}/yelp_nebulagraph_importer.yaml:/root/importer.yaml
-v ${PWD}/data:/root
vesoft/nebula-importer:v3.1.0
--config /root/importer.yaml
结束之后,我们可以看一下图上的统计:
~/.nebula-up/console.sh -e "USE yelp; SHOW STATS"然后,我们可以看到:
(root@nebula) [(none)]> USE yelp; SHOW STATS
+---------+---------------------------------------+---------+
| Type | Name | Count |
+---------+---------------------------------------+---------+
| "Tag" | "review" | 45954 |
| "Edge" | "shares_restaurant_in_one_month_with" | 1147232 |
| "Edge" | "shares_restaurant_rating_with" | 6805486 |
| "Edge" | "shares_user_with" | 98630 |
| "Space" | "vertices" | 45954 |
| "Space" | "edges" | 8051348 |
+---------+---------------------------------------+---------+
Got 6 rows (time spent 1911/4488 us)
目前,市面上的 LPA 标签传播算法都是用来做社区检测的,很少有实现是用来做标签拓展的(只有 SK-Learn 中有这个实现),这里,我们参考 Thibaud M https://datascience.stackexchange.com/users/77683/thibaud-m 给出来的实现。
原始的讨论参考:https://datascience.stackexchange.com/a/55720/138720
为了让这个算法跑的快一点,会从 NebulaGraph 里取一个点的子图,在这个小的子图上做标注的扩充:
首先,我们启动一个 Jupyter 的 Playground,
参考 https://github.com/wey-gu/nebula-dgl 中的 Playground 过程:
git clone https://github.com/wey-gu/nebula-dgl.git
cd nebula-dgl
# 运行 Jupyter Notebook
docker run -it --name dgl -p 8888:8888 --network nebula-net
-v "$PWD":/home/jovyan/work jupyter/datascience-notebook
start-notebook.sh --NotebookApp.token='nebulagraph'
访问:http://localhost:8888/lab/tree/work?token=nebulagraph
安装依赖(这些依赖在后边的 GNN 例子中也会被用到)
!python3 -m pip install git+https://github.com/vesoft-inc/nebula-python.git@8c328c534413b04ccecfd42e64ce6491e09c6ca8
!python3 -m pip install .
然后,我们从图中读取一个子图,从 2048 这个点开始探索两步内的所有边。
import torch
import json
from torch import tensor
from dgl import DGLHeteroGraph, heterograph
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
config = Config()
config.max_connection_pool_size = 2
connection_pool = ConnectionPool()
connection_pool.init([('graphd', 9669)], config)
vertex_id = 2048
client = connection_pool.get_session('root', 'nebula')
r = client.execute_json(
"USE yelp;"
f"GET SUBGRAPH WITH PROP 2 STEPS FROM {vertex_id} YIELD VERTICES AS nodes, EDGES AS relationships;")
r = json.loads(r)
data = r.get('results', [{}])[0].get('data')
columns = r.get('results', [{}])[0].get('columns')
# create node and nodedata
node_id_map = {} # key: vertex id in NebulaGraph, value: node id in dgl_graph
node_idx = 0
features = [[] for _ in range(32)] + [[]]
for i in range(len(data)):
for index, node in enumerate(data[i]['meta'][0]):
nodeid = data[i]['meta'][0][index]['id']
if nodeid not in node_id_map:
node_id_map[nodeid] = node_idx
node_idx += 1
for f in range(32):
features[f].append(data[i]['row'][0][index][f"review.f{f}"])
features[32].append(data[i]['row'][0][index]['review.is_fraud'])
rur_start, rur_end, rsr_start, rsr_end, rtr_start, rtr_end = [], [], [], [], [], []
for i in range(len(data)):
for edge in data[i]['meta'][1]:
edge = edge['id']
if edge['name'] == 'shares_user_with':
rur_start.append(node_id_map[edge['src']])
rur_end.append(node_id_map[edge['dst']])
elif edge['name'] == 'shares_restaurant_rating_with':
rsr_start.append(node_id_map[edge['src']])
rsr_end.append(node_id_map[edge['dst']])
elif edge['name'] == 'shares_restaurant_in_one_month_with':
rtr_start.append(node_id_map[edge['src']])
rtr_end.append(node_id_map[edge['dst']])
data_dict = {}
if rur_start:
data_dict[('review', 'shares_user_with', 'review')] = tensor(rur_start), tensor(rur_end)
if rsr_start:
data_dict[('review', 'shares_restaurant_rating_with', 'review')] = tensor(rsr_start), tensor(rsr_end)
if rtr_start:
data_dict[('review', 'shares_restaurant_in_one_month_with', 'review')] = tensor(rtr_start), tensor(rtr_end)
# construct a dgl_graph, ref: https://docs.dgl.ai/en/0.9.x/generated/dgl.heterograph.html
dgl_graph: DGLHeteroGraph = heterograph(data_dict)
# load node features to dgl_graph
dgl_graph.ndata['label'] = tensor(features[32])
# heterogeneous graph to heterogeneous graph, keep ndata and edata
import dgl
hg = dgl.to_homogeneous(dgl_graph, ndata=['label'])然后,我们用上边提到的 Torch Label Spreading 实现,应用到我们的图上。
from abc import abstractmethod
import torch
class BaseLabelPropagation:
"""Base class for label propagation models.
Parameters
----------
adj_matrix: torch.FloatTensor
Adjacency matrix of the graph.
"""
def __init__(self, adj_matrix):
self.norm_adj_matrix = self._normalize(adj_matrix)
self.n_nodes = adj_matrix.size(0)
self.one_hot_labels = None
self.n_classes = None
self.labeled_mask = None
self.predictions = None
@staticmethod
@abstractmethod
def _normalize(adj_matrix):
raise NotImplementedError("_normalize must be implemented")
@abstractmethod
def _propagate(self):
raise NotImplementedError("_propagate must be implemented")
def _one_hot_encode(self, labels):
# Get the number of classes
classes = torch.unique(labels)
classes = classes[classes != -1]
self.n_classes = classes.size(0)
# One-hot encode labeled data instances and zero rows corresponding to unlabeled instances
unlabeled_mask = (labels == -1)
labels = labels.clone() # defensive copying
labels[unlabeled_mask] = 0
self.one_hot_labels = torch.zeros((self.n_nodes, self.n_classes), dtype=torch.float)
self.one_hot_labels = self.one_hot_labels.scatter(1, labels.unsqueeze(1), 1)
self.one_hot_labels[unlabeled_mask, 0] = 0
self.labeled_mask = ~unlabeled_mask
def fit(self, labels, max_iter, tol):
"""Fits a semi-supervised learning label propagation model.
labels: torch.LongTensor
Tensor of size n_nodes indicating the class number of each node.
Unlabeled nodes are denoted with -1.
max_iter: int
Maximum number of iterations allowed.
tol: float
Convergence tolerance: threshold to consider the system at steady state.
"""
self._one_hot_encode(labels)
self.predictions = self.one_hot_labels.clone()
prev_predictions = torch.zeros((self.n_nodes, self.n_classes), dtype=torch.float)
for i in range(max_iter):
# Stop iterations if the system is considered at a steady state
variation = torch.abs(self.predictions - prev_predictions).sum().item()
if variation print(f"The method stopped after {i} iterations, variation={variation:.4f}.")
break
prev_predictions = self.predictions
self._propagate()
def predict(self):
return self.predictions
def predict_classes(self):
return self.predictions.max(dim=1).indices
class LabelPropagation(BaseLabelPropagation):
def __init__(self, adj_matrix):
super().__init__(adj_matrix)
@staticmethod
def _normalize(adj_matrix):
"""Computes D^-1 * W"""
degs = adj_matrix.sum(dim=1)
degs[degs == 0] = 1 # avoid division by 0 error
return adj_matrix / degs[:, None]
def _propagate(self):
self.predictions = torch.matmul(self.norm_adj_matrix, self.predictions)
# Put back already known labels
self.predictions[self.labeled_mask] = self.one_hot_labels[self.labeled_mask]
def fit(self, labels, max_iter=1000, tol=1e-3):
super().fit(labels, max_iter, tol)
class LabelSpreading(BaseLabelPropagation):
def __init__(self, adj_matrix):
super().__init__(adj_matrix)
self.alpha = None
@staticmethod
def _normalize(adj_matrix):
"""Computes D^-1/2 * W * D^-1/2"""
degs = adj_matrix.sum(dim=1)
norm = torch.pow(degs, -0.5)
norm[torch.isinf(norm)] = 1
return adj_matrix * norm[:, None] * norm[None, :]
def _propagate(self):
self.predictions = (
self.alpha * torch.matmul(self.norm_adj_matrix, self.predictions)
+ (1 - self.alpha) * self.one_hot_labels
)
def fit(self, labels, max_iter=1000, tol=1e-3, alpha=0.5):
"""
Parameters
----------
alpha: float
Clamping factor.
"""
self.alpha = alpha
super().fit(labels, max_iter, tol)
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
nx_hg = hg.to_networkx()
adj_matrix = nx.adjacency_matrix(nx_hg).toarray()
labels = hg.ndata['label']
# Create input tensors
adj_matrix_t = torch.FloatTensor(adj_matrix)
labels_t = torch.LongTensor(labels)
# Learn with Label Propagation
label_propagation = LabelPropagation(adj_matrix_t)
print("Label Propagation: ", end="")
label_propagation.fit(labels_t)
label_propagation_output_labels = label_propagation.predict_classes()
# Learn with Label Spreading
label_spreading = LabelSpreading(adj_matrix_t)
print("Label Spreading: ", end="")
label_spreading.fit(labels_t, alpha=0.8)
label_spreading_output_labels = label_spreading.predict_classes()现在咱们看看染色的传播效果:
color_map = {0: "blue", 1: "green"}
input_labels_colors = [color_map[int(l)] for l in labels]
lprop_labels_colors = [color_map[int(l)] for l in label_propagation_output_labels.numpy()]
lspread_labels_colors = [color_map[int(l)] for l in label_spreading_output_labels.numpy()]
plt.figure(figsize=(14, 6))
ax1 = plt.subplot(1, 4, 1)
ax2 = plt.subplot(1, 4, 2)
ax3 = plt.subplot(1, 4, 3)
ax1.title.set_text("Raw data (2 classes)")
ax2.title.set_text("Label Propagation")
ax3.title.set_text("Label Spreading")
pos = nx.spring_layout(nx_hg)
nx.draw(nx_hg, ax=ax1, pos=pos, node_color=input_labels_colors, node_size=50)
nx.draw(nx_hg, ax=ax2, pos=pos, node_color=lprop_labels_colors, node_size=50)
nx.draw(nx_hg, ax=ax3, pos=pos, node_color=lspread_labels_colors, node_size=50)
# Legend
ax4 = plt.subplot(1, 4, 4)
ax4.axis("off")
legend_colors = ["orange", "blue", "green", "red", "cyan"]
legend_labels = ["unlabeled", "class 0", "class 1", "class 2", "class 3"]
dummy_legend = [ax4.plot([], [], ls='-', c=c)[0] for c in legend_colors]
plt.legend(dummy_legend, legend_labels)
plt.show()可以看到最后画出来的结果:
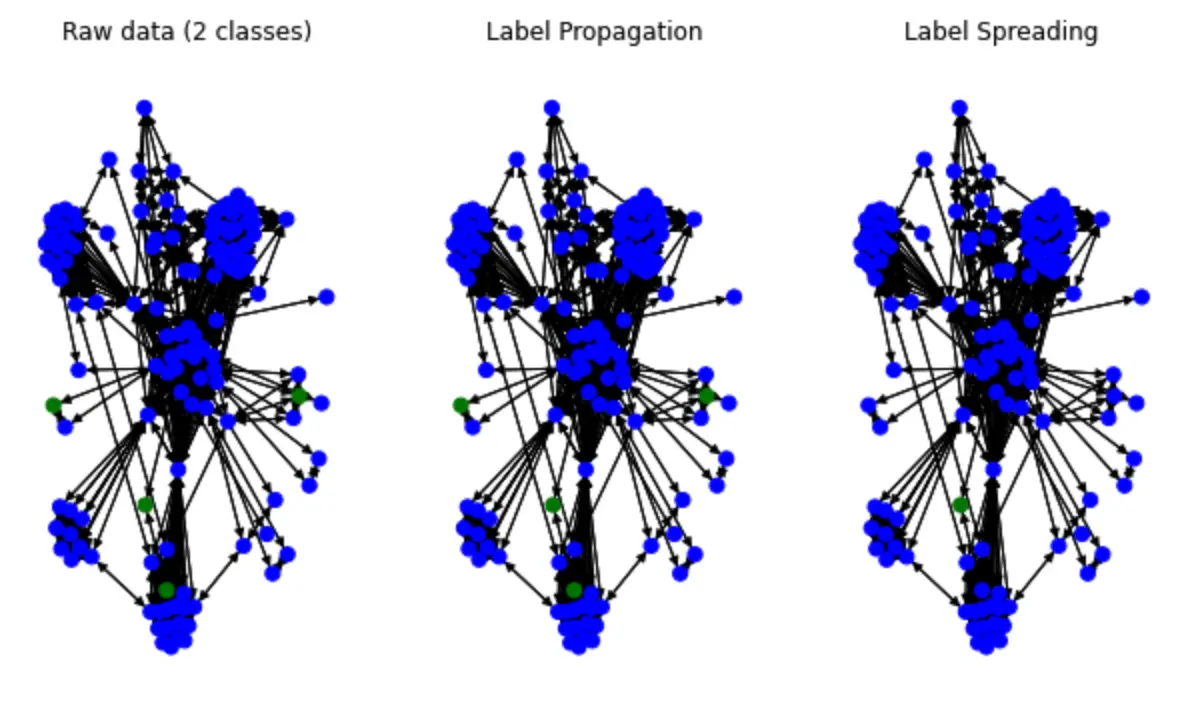
可以看到有一些蓝色标签被 Spread 开了,实际上我的这个例子的效果并不理想(因为这个例子里,绿色的才是重要的标签),不过我给的子图实在是太小了,也本不应该奢求有好的结果,只是为了个大家演示一下这个方法。
1.4 带有图特征的机器学习
在风控领域开始利用图的思想和能力之前,已经有很多利用机器学习的分类算法基于历史数据预测高风险行为的方法了,这些方法把记录中领域专家认为有关的信息(例如:年龄、学历、收入)作为特征,历史标注信息作为标签去训练风险预测模型。
那么读到的这里,我们是否会想到在这些方法的基础之上,如果把基于图结构的属性也考虑进来,作为特征去训练的模型可能更有效呢?答案也是肯定的,已经有很多论文和工程实践揭示这样的模型比未考虑图特征的算法更加有效。这些被尝试有效的图结构特征可能是实体的 PageRank 值、Degree 值或者是某一个社区发现算法得出的社区 id。
在生产上,我们可以定期从图谱中获得实时的全图信息,在图计算平台中分析运算获得所需特征,经过预定的数据管道,导入机器学习模型中周期获得新的风险提示,并将部分结果写回图谱方便其他系统和专家抽取、参考。
1.4.1 带有图特征的机器学习欺诈检测示例
这里,机器学习的方法我就不演示了,就是常见的分类方法,在此之上,我们可以在数据中通过图算法获得一些新的属性,这些属性再处理一下作为新的特征。我只演示一个社区发现的方法,我们可以对全图跑一个 Louvain,得出不同节点的社区归属,然后把社区的值当做一个分类处理成为数值的特征。
这个例子里我们还用 https://github.com/wey-gu/fraud-detection-datagen 这个数据,在此基础上,这个例子我用到了 Nebula-Algorithm 这个项目,它是一个 Spark 应用,可以在 NebulaGraph 图库上运行很多常用的图算法。
首先,我们部署 Spark 和 Nebula Algorithm,还是利用 Nebula-UP,一键部署:
curl -fsSL nebula-up.siwei.io/all-in-one.sh | bash -s -- v3 spark
集群起来之后,因为需要的配置文件我已经放在了 Nebula-UP 内部,我们只需要一行就可以运行算法啦!
cd ~/.nebula-up/nebula-up/spark && ls -l
docker exec -it sparkmaster /spark/bin/spark-submit
--master "local" --conf spark.rpc.askTimeout=6000s
--class com.vesoft.nebula.algorithm.Main
--driver-memory 4g /root/download/nebula-algo.jar
-p /root/louvain.conf
而最终的结果就在 sparkmaster 容器内的 /output 里:
# docker exec -it sparkmaster bash
ls -l /output
之后,我们可以对这个 Louvain 的图特征做一些处理,并开始传统的模型训练了。
1.5 图神经网络的方法
然而,这些图特征的方法的问题在于没能充分考虑关联关系,特征工程昂贵繁琐
注,这里,我们使用的的工具为 Deep Graph library(DGL),NebulaGraph 图数据库和他们之间的桥梁,Nebula-DGL。
-
DGL: https://www.dgl.ai/
-
Nebula-DGL: https://github.com/wey-gu/nebula-dgl 我也是这个库的作者

