
这个项目的动机是想看看在短短的几年时间里NLP领域的技术已经走了多远,特别是当它涉及到生成创造性内容的时候。通过生成动画概要,我探索了两种文本生成技术,首先是使用相对陈旧的LSTM,然后使用经过微调的GPT2。

在这篇文章中,您将看到AI创建这种废话开始的过程。。。
A young woman capable : a neuroi laborer of the human , where one are sent back home ? after defeating everything being their resolve the school who knows if all them make about their abilities . however of those called her past student tar barges together when their mysterious high artist are taken up as planned while to eat to fight !
这件艺术
A young woman named Haruka is a high school student who has a crush on a mysterious girl named Miki. She is the only one who can remember the name of the girl, and she is determined to find out who she really is.
为了能够了解本篇文章,你必须具备以下知识:
Python编程
Pytorch
RNNs的工作原理
Transformers
好吧,让我们看一些代码!
数据描述
这里使用的数据是从myanimelist中抓取的,它最初包含超过16000个数据点,这是一个非常混乱的数据集。所以我采取以下步骤清理:
删除了所有奇怪的动漫类型(如果你是一个动漫迷,你就会知道我在说什么)。
每个大纲在描述的最后都包含了它的来源(例如:source: myanimelist, source: crunchyroll等),所以我也删除了它。
基于电子游戏、衍生品或改编的动画都有非常少的概要总结,所以我删除了所有少于30的概要,我也删除了所有包含“衍生品”、“基于”、“音乐视频”、“改编”的概要。这样处理的逻辑是,这些类型的动画不会真正让我们的模型有创意。
我还删除了大纲字数超过300的动画。这只是为了使培训更容易(请查看GPT2部分以了解更多细节)。
删除符号。
一些描述也包含日文,所以这些也被删除了。
LSTM方式
传统的文本生成方法使用循环的LSTM单元。LSTM(长短期记忆)是专门设计来捕获顺序数据中的长期依赖关系的,这是常规的RNNs所不能做到的,它通过使用多个门来控制从一个时间步骤传递到另一个时间步骤的信息。
直观地说,在一个时间步长,到达LSTM单元的信息经过这些门,它们决定是否需要更新信息,如果它们被更新,那么旧的信息就会被忘记,然后新的更新的值被发送到下一个时间步长。要更详细地了解LSTMs,可以浏览我们发布的一些文章。
创建数据集
因此,在我们构建模型架构之前,我们必须标记概要并以模型接受的方式处理它们。
在文本生成中,输入和输出是相同的,只是输出标记向右移动了一步。这基本上意味着模型接受输入的过去的单词并预测下一个单词。输入和输出令牌分批传递到模型中,每个批处理都有固定的序列长度。我已经按照这些步骤来创建数据集:
创建一个配置类。
将所有的概要合并在一起。
标记对照表。
定义批数。
创建词汇,单词索引和索引到单词字典。
通过向右移动输入标记来创建输出标记。
创建一个生成器函数,它批量地输出输入和输出序列。
# code courtesy: https://machinetalk.org/2019/02/08/text-generation-with-pytorch/
class config:
# stores the required hyerparameters and the tokenizer for easy access
tokenizer = nltk.word_tokenize
batch_size = 32
seq_len = 30
emb_dim = 100
epochs = 15
hidden_dim = 512
model_path = 'lm_lrdecay_drop.bin'
def create_dataset(synopsis,batch_size,seq_len):
np.random.seed(0)
synopsis = synopsis.apply(lambda x: str(x).lower()).values
synopsis_text = ' '.join(synopsis)
tokens = config.tokenizer(synopsis_text)
global num_batches
num_batches = int(len(tokens)/(seq_len*batch_size))
tokens = tokens[:num_batches*batch_size*seq_len]
words = sorted(set(tokens))
w2i = {w:i for i,w in enumerate(words)}
i2w = {i:w for i,w in enumerate(words)}
tokens = [w2i[tok] for tok in tokens]
target = np.zeros_like((tokens))
target[:-1] = tokens[1:]
target[-1] = tokens[0]
input_tok = np.reshape(tokens,(batch_size,-1))
target_tok = np.reshape(target,(batch_size,-1))
print(input_tok.shape)
print(target_tok.shape)
vocab_size = len(i2w)
return input_tok,target_tok,vocab_size,w2i,i2w
def create_batches(input_tok,target_tok,batch_size,seq_len):
num_batches = np.prod(input_tok.shape)//(batch_size*seq_len)
for i in range(0,num_batches*seq_len,seq_len):
yield input_tok[:,i:i+seq_len], target_tok[:,i:i+seq_len]模型架构
我们的模型由一个嵌入层、一堆LSTM层(我在这里使用了3个层)、dropout层和最后一个输出每个词汇表标记的分数的线性层组成。我们还没有使用softmax层,你很快就会明白为什么。
因为LSTM单元也输出隐藏状态,所以模型也返回这些隐藏状态,以便在下一个时间步骤(下一批单词序列)中将它们传递给模型。此外,在每个epoch之后,我们需要将隐藏状态重置为0,因为在当前epoch的第一个time step中,我们不需要来自前一个epoch的最后一个time step的信息,所以我们也有一个“zero_state”函数。
class LSTMModel(nn.Module):
def __init__(self,hid_dim,emb_dim,vocab_size,num_layers=1):
super(LSTMModel,self).__init__()
self.hid_dim = hid_dim
self.emb_dim = emb_dim
self.num_layers = num_layers
self.vocab_size = vocab_size+1
self.embedding = nn.Embedding(self.vocab_size,self.emb_dim)
self.lstm = nn.LSTM(self.emb_dim,self.hid_dim,batch_first = True,num_layers = self.num_layers)
self.drop = nn.Dropout(0.3)
self.linear = nn.Linear(self.hid_dim,vocab_size) # from here we will randomly sample a word
def forward(self,x,prev_hid):
x = self.embedding(x)
x,hid = self.lstm(x,prev_hid)
x = self.drop(x)
x = self.linear(x)
return x,hid
def zero_state(self,batch_size):
return (torch.zeros(self.num_layers,batch_size,self.hid_dim),torch.zeros(self.num_layers,batch_size,self.hid_dim))训练
然后我们只需要定义训练函数,存储每个epoch的损失,并保存损失最大的模型。我们还在每个epoch之前调用零状态函数来重置隐藏状态。
我们使用的损失函数是交叉熵损失,这就是为什么我们没有通过显式softmax层的输出,因为这个损失函数计算内部。
所有的训练都是在GPU上完成的,下面是正在使用的参数(在config类中提供):
批次大小 = 32
最大序列长度 = 30
词嵌入维度 = 100
隐藏层尺寸 = 512
训练轮次 = 15
def loss_fn(predicted,target):
loss = nn.CrossEntropyLoss()
return loss(predicted,target)
#====================================================================================================================================
def train_fn(model,device,dataloader,optimizer):
model.train()
tk0 = tqdm(dataloader,position=0,leave=True,total = num_batches)
train_loss = AverageMeter()
hid_state,cell_state = model.zero_state(config.batch_size)
hid_state = hid_state.to(device)
cell_state = cell_state.to(device)
losses = []
for inp,target in tk0:
inp = torch.tensor(inp,dtype=torch.long).to(device)
target = torch.tensor(target,dtype=torch.long).to(device)
optimizer.zero_grad()
pred,(hid_state,cell_state) = model(inp,(hid_state,cell_state))
#print(pred.transpose(1,2).shape)
loss = loss_fn(pred.transpose(1,2),target)
hid_state = hid_state.detach()
cell_state = cell_state.detach()
loss.backward()
_ = torch.nn.utils.clip_grad_norm_(model.parameters(),max_norm=2) # to avoid gradient explosion
optimizer.step()
train_loss.update(loss.detach().item())
tk0.set_postfix(loss = train_loss.avg)
losses.append(loss.detach().item())
return np.mean(losses)
#====================================================================================================================================
def run():
device = 'cuda'
model = LSTMModel(vocab_size=vocab_size,emb_dim=config.emb_dim,hid_dim=config.hidden_dim,num_layers=3).to(device)
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer, mode = 'min', patience=2, verbose=True, factor=0.5)
epochs = config.epochs
best_loss = 999
for i in range(1,epochs+1):
train_dataloader = create_batches(batch_size=config.batch_size,input_tok=input_tok,seq_len=config.seq_len,target_tok=target_tok)
print('Epoch..',i)
loss = train_fn(model,device,train_dataloader,optimizer)
if loss
best_loss = loss
torch.save(model.state_dict(),config.model_path)
scheduler.step(loss)
torch.cuda.empty_cache()
return model生成动漫文本
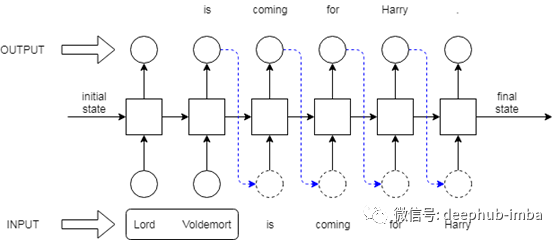
在文本生成步骤中,我们向模型提供一些输入文本,例如,' A young woman ',我们的函数将首先对其进行标记,然后将其传递到模型中。该函数还取我们想要输出的概要的长度。
模型将输出每个词汇表标记的分数。然后我们将对这些分数应用softmax将它们转换成概率分布。
然后我们使用top-k抽样,即从n个词汇表中选择概率最高的k个标记,然后随机抽样一个标记作为输出返回。
然后,该输出被连接到输出的初始输入字符串中。这个输出标记将成为下一个时间步骤的输入。假设输出是“capable”,然后我们连接的文本是“A young woman capable”。我们一直这样做,直到输出最后的结束标记,然后打印输出。
这里有一个很好的图表来理解模型在做什么
def inference(model,input_text,device,top_k=5,length = 100):
output = ''
model.eval()
tokens = config.tokenizer(input_text)
h,c = model.zero_state(1)
h = h.to(device)
c = c.to(device)
for t in tokens:
output = output+t+' '
pred,(h,c) = model(torch.tensor(w2i[t.lower()]).view(1,-1).to(device),(h,c))
#print(pred.shape)
for i in range(length):
_,top_ix = torch.topk(pred[0],k = top_k)
choices = top_ix[0].tolist()
choice = np.random.choice(choices)
out = i2w[choice]
output = output + out + ' '
pred,(h,c) = model(torch.tensor(choice,dtype=torch.long).view(1,-1).to(device),(h,c))
return output
# ============================================================================================================
device = 'cpu'
mod = LSTMModel(emb_dim=config.emb_dim,hid_dim=config.hidden_dim,vocab_size=vocab_size,num_layers=3).to(device)
mod.load_state_dict(torch.load(config.model_path))
print('AI generated Anime synopsis:')
inference(model = mod, input_text = 'In the ', top_k = 30, length = 100, device = device)
在上面的例子中,我给出的最大长度为100,输入文本为“In the”,这就是我们得到的输出
In the days attempt it 's . although it has , however ! what they believe that humans of these problems . it seems and if will really make anything . as she must never overcome allowances with jousuke s , in order her home at him without it all in the world : in the hospital she makes him from himself by demons and carnage . a member and an idol team the power for to any means but the two come into its world for what if this remains was to wait in and is n't going ! on an
这在语法上似乎是正确的,但却毫无意义。LSTM虽然更善于捕捉长期依赖比基本RNN但他们只能看到几步(字)或向前迈了几步,如果我们使用双向RNNs捕获文本的上下文因此生成很长的句子时,我们看到他们毫无意义。
GPT2方式
一点点的理论
Transformers在捕获所提供的文本片段的上下文方面做得更好。他们只使用注意力层(不使用RNN),这让他们更好地理解文本的上下文,因为他们可以看到尽可能多的时间步回(取决于注意力)。注意力有不同的类型,但GPT2所使用的注意力,是语言建模中最好的模型之一,被称为隐藏的自我注意。
GPT2没有同时使用transformer 编码器和解码器堆栈,而是使用了一个高栈的transformer 解码器。根据堆叠的解码器数量,GPT2转换器有4种变体。
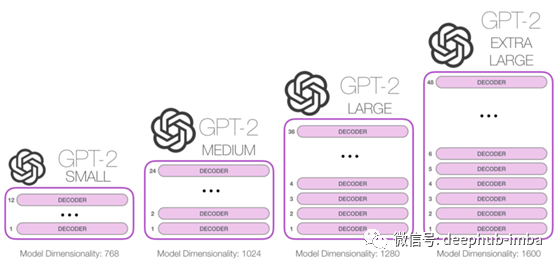
每个解码器单元主要由2层组成:
Masked 的自我关注
前馈神经网络
在每一步之后还有一个层规范化步骤和一个残差连接。
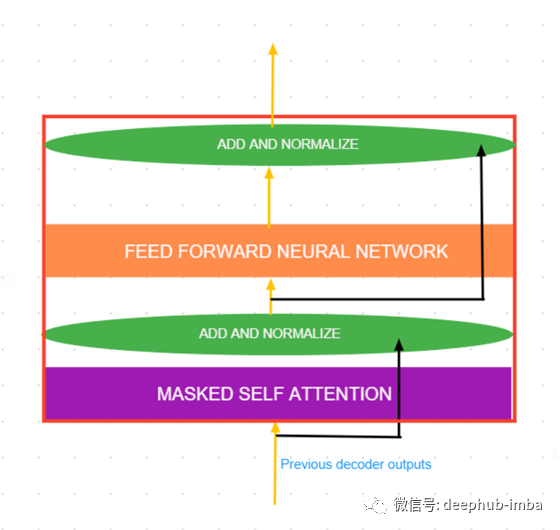
直观地说,自注意分数给了我们当前时间步长的单词应该给予其他单词的重要性或注意(过去的时间步或者未来的时间步取决于注意力)。
然而,在隐藏的自注意中,我们并不关心下一个或未来的单词。因此,transformer 解码器仅关注当前和过去的单词以及将来的单词。盖。
这里有一个关于这个想法的漂亮的表述……
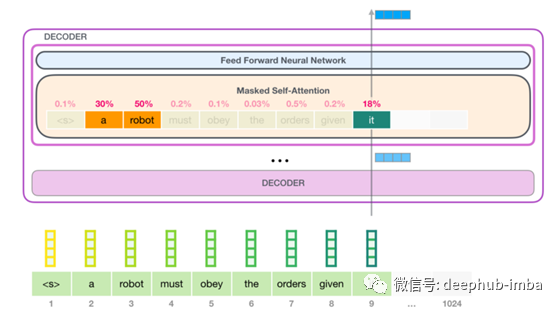
在上面的示例中,当前单词是“ it”,并且您可以看到单词“ a”和“ robot”具有很高的注意力得分。这是因为“ it”被用来指“robot”,“ a”也被指。
您必须已经注意到上面输入文本开头的标记。仅用于标记输入字符串的开头。传统上,使用代替令牌。
您还必须注意的另一件事是,这与传统语言建模相似,在传统语言建模中,可以看到当前令牌和过去令牌,并预测下一个令牌。然后,将该预测令牌添加到输入中,然后再次预测下一个令牌。
代码
我已经将GPT2与Hugging Face库中的线性模型一起用于文本生成。在这4个变体中,我使用了GPT2 small(具有117M个参数)。
我已经在Google Colab上训练了模型,训练中的主要问题是弄清楚批大小和最大序列长度,以便在GPU上进行训练时不会出现内存不足的情况,批大小为10,最大序列长度为 300终于可以工作了。
因此,我也删除了带有300个以上单词的提要,以便当我们生成提要直到300时,它实际上是完整的。
创建数据集
为了进行微调,首要任务是获取所需格式的数据,Pytorch中的数据加载器使我们可以非常轻松地做到这一点。
步骤如下:
使用上面定义的clean_function清理数据。
每个提要后都添加标记。
使用HuggingFace的GPT2Tokenizer对每个大纲进行标记。

