
引言
我们很高兴地宣布由 Technology Innovation Institute (TII) 训练的开源大模型 Falcon 180B 登陆 Hugging Face! Falcon 180B 为开源大模型树立了全新的标杆。作为当前最大的开源大模型,有180B 参数并且是在在 3.5 万亿 token 的 TII RefinedWeb 数据集上进行训练,这也是目前开源模型里最长的单波段预训练。
你可以在 Hugging Face Hub 中查阅模型以及其 Space 应用。
模型:
https://hf.co/tiiuae/falcon-180B
https://hf.co/tiiuae/falcon-180B-chat
Space 应用地址:
https://hf.co/spaces/tiiuae/falcon-180b-demo
从表现能力上来看,Falcon 180B 在自然语言任务上的表现十分优秀。它在开源模型排行榜 (预训练) 上名列前茅,并可与 PaLM-2 等专有模型相差无几。虽然目前还很难给出明确的排名,但它被认为与 PaLM-2 Large 不相上下,这也使得它成为目前公开的能力最强的 LLM 之一。
我们将在本篇博客中通过评测结果来探讨 Falcon 180B 的优势所在,并展示如何使用该模型。
Falcon 180B 是什么?
从架构维度来看,Falcon 180B 是 Falcon 40B 的升级版本,并在其基础上进行了创新,比如利用 Multi-Query Attention 等来提高模型的可扩展性。可以通过回顾 Falcon 40B 的博客 Falcon 40B 来了解其架构。Falcon 180B 是使用 Amazon SageMaker 在多达 4096 个 GPU 上同时对 3.5 万亿个 token 进行训练,总共花费了约 7,000,000 个 GPU 计算时,这意味着 Falcon 180B 的规模是 Llama 2 的 2.5 倍,而训练所需的计算量是 Llama 2 的 4 倍。
其训练数据主要来自 RefinedWeb 数据集 (大约占 85%),此外,它还在对话、技术论文和一小部分代码 (约占 3%) 等经过整理的混合数据的基础上进行了训练。这个预训练数据集足够大,即使是 3.5 万亿个标记也只占不到一个时期 (epoch)。
已发布的 聊天模型 在对话和指令数据集上进行了微调,混合了 Open-Platypus、UltraChat 和 Airoboros 数据集。
‼️ 商业用途: Falcon 180b 可用于商业用途,但条件非常严格,不包括任何“托管用途”。如果您有兴趣将其用于商业用途,我们建议您查看 许可证 并咨询您的法律团队。
Falcon 180B 的优势是什么?
Falcon 180B 是当前最好的开源大模型。在 MMLU上 的表现超过了 Llama 2 70B 和 OpenAI 的 GPT-3.5。在 HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC 及 ReCoRD 上与谷歌的 PaLM 2-Large 不相上下。
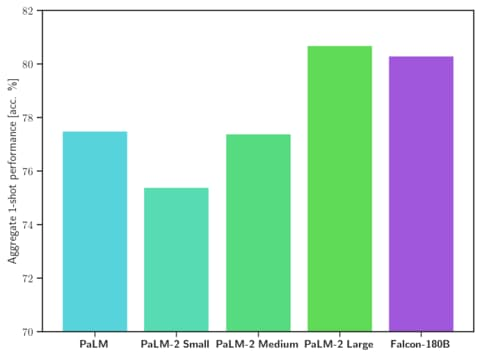
它在 Hugging Face 开源大模型榜单上以 68.74 的成绩被认为是当前评分最高的开放式大模型,评分超过了 Meta 的 LlaMA 2 (67.35)。
| Model | Size | Leaderboard score | Commercial use or license | Pretraining length |
|---|---|---|---|---|
| Falcon | 180B | 68.74 |

